
Indice
|
Nota sulla formattazione dei listati ………………………………………………………... |
IV |
|
|
Nota sulle specifiche di riferimento ……………………………………………………….. |
IV |
1 CENNI STORICI
|
1.1 |
Linguaggi di markup ………………………………………………………………………….. |
1 |
|
1.2 |
Nascita di SGML ……………………………………………………………………………... |
3 |
|
1.3 |
La più utilizzata applicazione SGML: HTML |
|
|
1.3.1 Origine di HTML ………………………………………………………………………. |
4 |
|
|
1.3.2 Il successo di HTML …………………………………………………………………… |
4 |
|
|
1.4 |
Sviluppo di XML a partire da SGML |
|
|
1.4.1 Problemi nell’introduzione di SGML nel Web ………………………………………… |
5 |
|
|
1.4.2 Il gruppo di lavoro nel consorzio W3 ………………………………………………….. |
5 |
|
|
1.4.3 La situazione attuale …………………………………………………………………… |
6 |
|
|
1.4.4 Composizione del gruppo di lavoro XML ……………………………………………… |
6 |
|
|
1.5 |
Conclusioni …………………………………………………………………………………… |
7 |
2 LIMITI DI HTML
|
2.1 |
HTML non è estensibile |
|
|
2.1.1 Tag e attributi in HTML …………………………………………………………….. |
8 |
|
|
2.1.2 Fogli di stile in HTML ……………………………………………………………… |
8 |
|
|
2.1.3 Estensioni non ufficiali di HTML …………………………………...………………. |
9 |
|
|
2.2 |
HTML è orientato solo alla descrizione dei documenti …………………………………… |
9 |
|
2.3 |
HTML non consente visualizzazioni diverse dei documenti ……………………………… |
10 |
|
2.4 |
HTML non ha una struttura semantica ……………………………………………………. |
11 |
|
2.5 |
Problemi nella conversione in HTML da altri formati ……………………………………. |
11 |
|
2.6 |
Problemi relativi ai link |
|
|
2.6.1 HTML consente solo collegamenti semplici ...……………………………………… |
12 |
|
|
2.6.2 I link scomparsi ...…………………………………………………………………… |
13 |
|
|
2.7 |
HTML si sta evolvendo anche troppo rapidamente ……………………………………….. |
14 |
|
2.8 |
Conclusioni ………………………………………………………………………………... |
15 |
3 STRUTTURA E SINTASSI DI XML
|
3.1 |
Il processo di codifica XML ………………………………………………………...…….. |
16 |
|
3.2 |
La sintassi di XML |
|
|
3.2.1 Sintassi dei tag …………………………………………………………………...…. |
17 |
|
|
3.2.2 Obblighi sintattici imposti da XML ………………………………...……………...... |
18 |
|
|
3.3 |
Documenti validi e ben formati …………………………………………………………… |
19 |
|
3.4 |
Prologo ……………………………………………………..……………………………… |
20 |
|
3.4.1 Dichiarazione XML………………………………………………………..……...…. |
20 |
|
|
3.4.2 Dichiarazione di tipo di documento …...……………………………...………...…... |
21 |
|
|
3.5 |
Entità predefinite ……………………..……………………………………………………. |
22 |
|
3.6 |
Riferimenti ai caratteri ……………………………….……………………………………. |
23 |
|
3.7 |
Istruzioni di elaborazione ………………………………………………………………….. |
23 |
|
3.8 |
Commenti ………………………………………………………………………………….. |
24 |
|
3.9 |
Conversione di un documento HTML in un documento XML ben formato ……………… |
24 |
4 DOCUMENT TYPE DEFINITION (DTD)
|
4.1 |
Dichiarazione degli elementi ……………………………………………………………… |
31 |
|
4.1.1 Esempi di dichiarazione degli elementi …………………………………………….. |
32 |
|
|
4.2 |
Dichiarazione degli attributi ………………………………………………………………. |
33 |
|
4.2.1 Riferimenti incrociati ……………………………………………………………….. |
35 |
|
|
4.3 |
Entità |
|
|
4.3.1 Entità interne ……………………………………………………………………….. |
36 |
|
|
4.3.2 Entità esterne ………………………………………...……………………………... |
38 |
|
|
4.3.3 Entità parametro ….………………………………...………………………………. |
39 |
|
|
4.4 |
Annotazioni ………………………………………………………………………………... |
40 |
|
4.5 |
Creazione della DTD per un documento XML ben formato ……………………………… |
40 |
|
4.6 |
Spazi dei nomi ……………………………………………………………………………... |
42 |
|
4.7 |
Un’alternativa alla DTD: lo schema XML-Data |
|
|
4.7.1 Difetti della DTD …………………………………………………………………… |
43 |
|
|
4.7.2 Uso dello schema …………………………………………………………………… |
44 |
|
|
4.7.3 Dichiarazione degli elementi ………………………………………...……………... |
44 |
|
|
4.7.4 Dichiarazione degli attributi …………………………………...…………………… |
46 |
|
|
4.8 |
Conclusioni ………………………………………………………………………………... |
46 |
5 EXTENSIBLE STYLESHEET LANGUAGE (XSL)
|
5.1 |
Associazione di tag HTML agli elementi XML …………………………………………... |
48 |
|
5.2 |
Visualizzazione di più elementi con lo stesso nome ………………………………………. |
49 |
|
5.3 |
Visualizzazione dei valori degli attributi ………………………………………………….. |
50 |
|
5.4 |
Fogli di stile contenenti più modelli ………………………………………………………. |
51 |
|
5.5 |
Visualizzazione dei nomi di elementi ed attributi. Carattere jolly ………………………… |
53 |
|
5.6 |
Costruzione di un foglio di stile …………………………………………………………… |
55 |
|
5.7 |
Isole di dati XML ………………………………………………………………………….. |
57 |
|
5.8 |
Trasformazione di documenti XML attraverso XSL |
|
|
5.8.1 Estrazione di un sottoalbero da un documento XML ………………………………. |
59 |
|
|
5.8.2 Aggiunta di nuovi nodi ad un documento XML …………………………………….. |
60 |
|
|
5.9 |
Conclusioni ………………………………………………………………………………... |
61 |
6 GESTIONE DI UNA SEMPLICE BASE DI DATI CON XML
|
6.1 |
Spazio dei nomi datatypes …………………………………………………………………. |
62 |
|
6.1.1 Tipi di attributi negli schemi di XML-Data…………………………………………. |
64 |
|
|
6.2 |
Rappresentazione in XML di una semplice base di dati |
|
|
6.2.1 Definizione dello schema …………………………………………………………… |
64 |
|
|
6.2.2 Definizione dello schema tramite una DTD ………………………………………… |
66 |
|
|
6.2.3 Documento XML contenente i dati ………………………………………...……….. |
67 |
|
|
6.2.4 Foglio di stile per la visualizzazione dei dati …………………………………...….. |
69 |
|
|
6.3 |
Pattern di XSL ……………………………………………………………………………... |
71 |
|
6.4 |
Interrogazioni semplici con XSL |
|
|
6.4.1 Interrogazione 1 …………………………………………………………………….. |
73 |
|
|
6.4.2 Interrogazione 2 …………………………………………………………………….. |
73 |
|
|
6.4.3 Interrogazione 3 …………………………………………………………………….. |
74 |
|
|
6.5 |
Join di tabelle |
|
|
6.5.1 Interrogazione 4 …………………………………………………………………….. |
75 |
|
|
6.5.2 Interrogazione 5 (Join completo) …………………………………………………… |
76 |
|
|
6.6 |
Interrogazioni di tipo matematico |
|
|
6.6.1 Interrogazione 6 …………………………………………………………………….. |
78 |
|
|
6.6.2 Interrogazione 7 …………………………………………………………………….. |
79 |
|
|
6.6.3 Interrogazione 8 …………………………………………………………………….. |
80 |
|
|
6.7 |
Ordinamenti …………………………………………………………………………….…. |
81 |
|
6.7.1 Interrogazione 9 …………………………………………………………………….. |
81 |
|
|
6.7.2 Interrogazione 10 …………………………………………………………………… |
82 |
|
|
6.8 |
Costrutti condizionali di XSL ……………………………………………………………... |
84 |
|
6.8.1 Utilizzo dell'elemento xsl:if ……………………………………………………….… |
84 |
|
|
6.8.2 Utilizzo dell'elemento xsl:choose …………………………………………………… |
85 |
|
|
6.9 |
Conclusioni ………………………………………………………………………………... |
87 |
7 XLINK, XPOINTER E MATHML
|
7.1 |
XLink …………………………………………………………………………………….. |
90 |
|
7.2 |
Collegamenti semplici …………………………………………………………………… |
90 |
|
7.3 |
Collegamenti estesi |
|
|
7.3.1 Sintassi …………………………………………………………………………….. |
93 |
|
|
7.3.2 Introduzione degli archi nei collegamenti estesi ………………………………….. |
94 |
|
|
7.4 |
Gruppi di collegamenti estesi ……………………………………………………………. |
95 |
|
7.5 |
Cenni sul linguaggio XPointer |
|
|
7.5.1 Compatibilità con XPath ………………………………………………………….. |
97 |
|
|
7.5.2 Selezione di un gruppo di elementi ……………………………………………….. |
98 |
|
|
7.5.3 Selezione di stringhe ………………………………………………………………. |
98 |
|
|
7.6 |
Prime applicazioni di XML |
|
|
7.6.1 Vocabolari XML …………………………………………………………………... |
99 |
|
|
7.6.2 Cenni sul linguaggio MathML …………………………………………………….. |
100 |
|
Appendice A: Guida rapida ……………………………………………………………. |
103 |
|
|
Appendice B: Riferimenti bibliografici ……………………………………………….. |
108 |
Nota sulla formattazione dei listati
Tutti i listati di questa tesina sono scritti con il carattere "Courier New". Per migliorare la loro leggibilità, ho pensato di utilizzare diversi formati di questo carattere, allo scopo di distinguere le parti con significati diversi all’interno di ciascun listato. Ho seguito questo criterio:
| Grassetto: markup imposto dai linguaggi, compresi simboli e segni di punteggiatura. Parole chiave degli script. | |
| Grassetto corsivo: markup definito dall'utente. Funzioni definite dall’utente negli script. | |
| Normale: testo contenuto nel documento e costanti degli script. | |
| Corsivo: valori degli attributi, esclusi quelli imposti dai linguaggi. Variabili degli script. |
Nota sulle specifiche di riferimento
XML è uno standard approvato dal W3C. Al contrario, i linguaggi ad esso collegati sono ancora in fase di sviluppo: infatti il W3C pubblica continuamente nuove bozze di lavoro, talvolta molto diverse dalle loro versioni precedenti. Per questo motivo vorrei precisare che la stesura di questa tesina è stata completata il 30 settembre 1999 e quindi si basa sulle specifiche riportate in questa tabella:
|
Linguaggio |
Versione |
Tipo di specifica |
Data |
Riferimento bibliografico |
|
XML |
1.0 |
Raccomandazione |
10/2/1998 |
[6] |
|
XSLT |
1.0 |
Bozza di lavoro |
13/8/1999 |
[26] |
|
XPath |
1.0 |
Bozza di lavoro |
13/8/1999 |
[38] |
|
XLink |
Bozza di lavoro |
26/7/1999 |
[39] |
|
|
XPointer |
Bozza di lavoro |
9/7/1999 |
[43] |
|
|
MathML |
1.01 |
Raccomandazione |
7/7/1999 |
[45] |
1 CENNI STORICI
1.1 Linguaggi di markup
I documenti elettronici, compreso il file di questa tesina, contengono dei codici di formattazione, ossia dei caratteri o delle stringhe speciali, generati dal programma di scrittura, che indicano i modi di visualizzazione e di stampa del testo. Tali codici sono diversi a seconda del programma che ha generato il file, e rendono il documento inutilizzabile, se non si dispone di un programma compatibile con quello che ha prodotto il file. Queste incompatibilità sono un problema attuale, basti pensare:
| alla miriade di formati esistenti (HTML, RTF, LaTec , documenti di Word, file di Acrobat, ecc.); | |
| alle incompatibilità fra versioni diverse dello stesso programma (chiunque ha Office ’95 può avere problemi ad utilizzare un documento scritto con Office ’97, se per quest’ultimo non è stata seguita un’opportuna procedura di salvataggio). |
In generale, i formati di memorizzazione dei documenti elettronici si possono dividere in due categorie [19]:
Tralasciamo i formati chiusi e tra i formati aperti soffermiamoci in particolare sui linguaggi di markup.
Un linguaggio di markup ha la caratteristica di avere i codici di formattazione costituiti da marcatori o tag, che sono stringhe di caratteri aggiunte al testo, per darne un’interpretazione semantica. All’interno dei tag possono comparire ulteriori informazioni, che vengono associate al testo tramite gli attributi, ciascuno dei quali ha un valore. Il testo con l’aggiunta dei marcatori si definisce codice del documento.
Per avere un’idea delle enormi differenze fra i vari linguaggi di markup, consideriamo un breve documento con qualche elemento di formattazione:
A: Alessandro
Da: Luca
CC: Ezio
Titolo: Prova
Questo è un esempio di e-mail, che serve a mostrare le differenze fra i linguaggi di markup.
Vediamo il codice corrispondente a questo documento nei tre più usati linguaggi di markup:
{\rtf1\ansi\deff0\deftab720{\fonttbl{\f0\fswiss MS Sans Serif;} {\f1\froman\fcharset2 Symbol;}
{\f2\froman\fprq2 Times New Roman;}
{\f3\froman Times New Roman;}}
{\colortbl\red0\green0\blue0;}
\deflang1040\pard\plain\f2\fs24\b
A: \plain\f2\fs24 Alessandro\par \plain\f2\fs24\b Da: \plain\f2\fs24 Luca
\par \plain\f2\fs24\b CC: \plain\f2\fs24 Ezio
\par \plain\f2\fs24\b Titolo: \plain\f2\fs24\i
Prova\plain\f2\fs24\b
\par
\par \plain\f2\fs24 Questo \'e8 un esempio di e-mail, che serve a mostrare le differenze fra i linguaggi di markup.
\par \pard\plain\f3\fs20
\par }
La sintassi è pesante e rende il documento poco leggibile: il markup supera abbondantemente il testo, anche in un documento così semplice. I tag sono molto lunghi e si notano frequenti ripetizioni delle stesse informazioni, come il tipo di font (f2) o il formato del carattere (fs24). Questo perché viene specificata completamente la formattazione di tutte le stringhe di testo.
\begin{document}
Le differenze sono molto evidenti e, ovviamente, si ripercuotono in difficoltà di conversione tra un formato e l’altro.
1.2 Nascita di SGML
Il problema dell’incompatibilità tra formati era già sentito negli anni ’60 ed ha portato alla definizione di SGML (Standard Generalized Markup Language) ad opera di Charles Goldfarb. Da SGML sono stati inoltre sviluppati sia HTML, sia XML, linguaggio, quest’ultimo, che dovrebbe diventare il formato universale di scambio di dati su Web, affiancandosi all’HTML e superandone i limiti [2].
Nella tabella che segue, riassumiamo l’evoluzione di SGML e delle sue prime applicazioni [4]:
| Fine anni ‘60 |
Progetto "GenCode". Lo scopo era quello di diffondere l’utilizzo di codici di formattazione descrittivi, al posto di caratteri poco comprensibili. |
|
1969 |
Charles Goldfarb, Edward Mosher e Raymond Lorie svilupparono per conto della IBM il GML (Generalized Markup Language), il primo linguaggio adatto a documenti di qualsiasi tipo. |
|
1974 |
Goldfarb ideò il concetto di analizzatore di validità, strumento in grado di verificare la correttezza del markup. |
|
1980 |
Prima bozza di lavoro su SGML. |
|
1984 |
L’International Organization for Standardization (ISO) autorizzò la produzione dello standard SGML. |
|
1985 |
Nacque il primo gruppo internazionale di utenti SGML. SGML venne adoperato dalla Comunità Europea per le comunicazioni ufficiali. |
|
1986 |
SGML divenne uno standard internazionale (ISO 8879) |
|
1987 |
L’associazione degli editori americani (AAP) sviluppò un’applicazione SGML per la pubblicazione di articoli, giornali e libri. |
|
1988 |
Il dipartimento della difesa degli Stati Uniti sviluppò lo standard militare CALS (Computer-aided Acquisition and Life-cycle Support), basato su SGML. |
1.3 La più utilizzata applicazione SGML: HTML
1.3.1 Origine di HTML
Nel 1989, un ricercatore del CERN di Ginevra, Tim Barners Lee, presentò ai dirigenti del laboratorio una relazione intitolata "Information Management: a proposal" [7]. Lo scopo di Barners Lee era di sviluppare un sistema di pubblicazione e reperimento dell'informazione distribuito su una rete geografica, in grado di tenere in contatto la comunità mondiale dei fisici.
Un collega di Barners Lee, Anders Berglund, uno dei primi sostenitori di SGML, gli consigliò di utilizzare una sintassi simile a quella di SGML [1]. Essi partirono da una semplice definizione di tipo di documento (DTD) SGML, contenuta in un manuale IBM scritto nel 1978 da Goldfarb. Nacque così l'HyperText Markup Language (HTML), sul quale Barners Lee costruì il proprio sistema ipertestuale, che chiamò World Wide Web (WWW).
 Tim Barners Lee, attuale direttore del W3 Consortium
Tim Barners Lee, attuale direttore del W3 Consortium
La DTD è di fondamentale importanza sia per SGML, che per XML, in quanto fornisce la descrizione formale della struttura di un documento. Il concetto di DTD sarà trattato esplicitamente nel capitolo 4.
Si noti che la DTD di HTML fu definita formalmente solo tra il 1992 e il 1993 da Dan Connolly, con il nome di "HTML 1.0". Quando arrivò questa prima DTD, esistevano già nel Web migliaia di pagine contenenti codice HTML non conforme ad essa.
1.3.2 Il successo di HTML
In confronto allo sviluppo di SGML, che aveva richiesto quasi vent'anni, la realizzazione di HTML richiese pochissimo tempo, grazie alla sua semplicità. E fu sicuramente tale semplicità la causa fondamentale dello strepitoso successo di HTML e, con esso, del Web, divenuto in pochi anni il sistema informativo più completo, sebbene caotico, che sia mai esistito.
In questa tabella sono riassunti le principali tappe dell'evoluzione di HTML [9]:
|
1989 |
È proposto il progetto WWW al CERN di Ginevra |
|
Ottobre 1991 |
Viene creata la mailing list www-talk@info.cern.ch, per raccogliere suggerimenti utili allo sviluppo di HTML |
|
Marzo 1992 |
Inizia lo sviluppo di HTML 1.0 |
|
1993 |
Versione finale di HTML 1.0. Si inizia a lavorare immediatamente alla versione 2.0 |
|
Inizio 1993 |
Viene rilasciato il primo browser: NCSA Mosaic. È l'evento che segna il decollo del Web |
|
Settembre 1995 |
HTML 2.0 |
|
Novembre 1995 |
Viene implementato l'invio di file utilizzando i form |
|
Marzo 1996 |
Bozza di HTML 3.0 |
|
Maggio 1996 |
Viene introdotta la gestione di tabelle in HTML |
|
Gennaio 1997 |
HTML 3.2. Internazionalizzazione di HTML |
|
Dicembre 1997 |
HTML 4.0 |
|
Agosto 1999 |
XHTML 1.0 (vedi §3.9) ed HTML 4.01 |
Lo sviluppo di HTML è stato portato avanti dal 1994 dall'IETF working group (IETF è l'acronimo di Internet Engineering Task Force), che si è poi rivelato insufficiente per la mole di lavoro necessaria, ed è stato assorbito alla fine del 1996 dal W3 Consortium [8].
1.4 Sviluppo di XML a partire da SGML
1.4.1 Problemi nell'introduzione di SGML nel Web
Grazie all’esplosione in tutto il mondo della popolarità del Web, molti utilizzatori di HTML si sono resi conto dei numerosi limiti di cui soffre:
| non estensibilità, | |
| impossibilità di fornire visualizzazioni differenziate, | |
| mancanza di una struttura semantica, | |
| presenza dei soli collegamenti unidirezionali; |
limiti che verranno discussi in dettaglio nel prossimo capitolo. Con il passare degli anni (e delle versioni di HTML), gli esperti di SGML pensarono di poter utilizzare il loro linguaggio per la pubblicazione di documenti su Web [10]. Infatti HTML è una semplice applicazione di SGML.
Ma gli stessi esperti, in seguito, stabilirono che introdurre direttamente SGML su Web avrebbe comportato dei notevoli problemi [11]:
| L’uso generico di SGML avrebbe richiesto una vera e propria ristrutturazione dell'attuale architettura del World Wide Web; | |
| L’implementazione di un browser SGML per tutte le possibili applicazioni sarebbe stata notevolmente complicata dal punto di vista computazionale rispetto ad un browser HTML. Pur risolvendo i problemi tecnici, la complessità di un programma simile, e del linguaggio SGML stesso, avrebbero limitato notevolmente l'efficienza del trasferimento di informazioni attraverso Internet. | |
| L’apprendimento di SGML è decisamente più ostico rispetto a quello di HTML. Questo è un grosso ostacolo per gli sviluppatori di pagine Web in HTML. |
I più noti browser SGML sono Panorama SGML e MultidocPro, sviluppati rispettivamente dalle software house Interleaf e Citec.
1.4.2 Il gruppo di lavoro nel Consorzio W3
Nell'estate del 1996, Jon Bosak, attualmente a capo del settore informativo della Sun Microsystem, convinse il W3C a formare un gruppo di lavoro sull'uso di SGML sul Web [10]. Egli fu il presidente di questo comitato, chiamato inizialmente "SGML Editorial Review Board" e scelse personalmente i migliori specialisti di SGML.
Nell'agosto del 1996 si svolse una conferenza sull'implementazione di SGML nel Web [12]. I risultati della discussione furono due:
Già nel novembre del 1996, il gruppo di lavoro del W3C creò una forma semplificata di SGML, comprendente le caratteristiche già ampiamente sperimentate di SGML con una complessità ridotta [10]. Questo linguaggio fu chiamato XML (eXtensible Markup Language), proprio per enfatizzare la principale differenza con HTML, che è un linguaggio di markup con dei tag definiti e non modificabili.
1.4.3 La situazione attuale
La nascita "ufficiale" di XML risale al marzo del 1997, quando Jon Bosak pubblicò il suo "manifesto": un articolo intitolato "XML, Java e il futuro del Web" [15]. Il gruppo di lavoro da lui diretto stabilì che la composizione delle specifiche di XML si sarebbe svolta in tre fasi:
Si noti che XLL ed XSL furono concepiti come dei particolari linguaggi derivati da XML, con le proprie DTD. La situazione dello sviluppo di questi linguaggi è la seguente:
Per quanto riguarda XSL, la standardizzazione si può ritenere abbastanza vicina, basti pensare che XSL, insieme ad XML, è parzialmente supportato da Explorer 5, il nuovo browser della Microsoft rilasciato nel marzo 1999. Viceversa, la situazione sui collegamenti è in costante mutamento e si può affermare che il modo esatto in cui i collegamenti dovrebbero essere implementati nell'XML è ancora in fase di discussione [5].
1.4.4 Composizione del gruppo di lavoro XML
Per quanto si è visto finora, sembra che lo sviluppo di XML riguardi esclusivamente il W3C. Viceversa, il gruppo di lavoro per la standardizzazione di XML è formato dai rappresentanti di numerose importanti organizzazioni, ciascuna delle quali ha un forte interesse nel produrre ed utilizzare strumenti basati su XML [6]. Le più famose tra esse sono:
1.5 Conclusioni
Al termine di questa introduzione storica su XML è essenziale ribadire la distinzione fra SGML, HTML ed XML [10]:
| SGML è un linguaggio per la descrizione di documenti di qualsiasi tipo; | |
| HTML è una particolare applicazione di SGML per la presentazione di documenti attraverso "pagine Web"; | |
| XML è un linguaggio per la descrizione dei documenti su Web, ottenuto semplificando SGML. |
2 LIMITI DI HTML
2.1 HTML non è estensibile
2.1.1 Tag e attributi in HTML
HTML non permette agli utenti di specificare dei propri tag o attributi nei documenti, allo scopo di personalizzarli o di introdurvi una propria semantica [15].
Per capire che cosa siano precisamente tag ed attributi in HTML, mostriamo un semplicissimo esempio:
<h1 align=center>
Titolo Principale</h1>il cui risultato è:
Il tag nel nostro caso è <h1>, che significa intestazione (header) di tipo 1, cioè di massima importanza. L'attributo è align, con valore center ed indica al browser che il testo etichettato dal tag va allineato centralmente. Il testo associato al tag è semplicemente la stringa "Titolo Principale" contenuta tra il tag di apertura <h1> e il tag di chiusura </h1>.
Se avessimo bisogno di un titolo con un carattere ancora più grande? Il tag <h0> non è previsto e noi non abbiamo la possiblità di definirlo. Naturalmente è possibile ottenere caratteri più grandi di quelli appena visti, ma bisogna utilizzare degli altri tag previsti dal linguaggio HTML, oppure dei fogli di stile, introdotti da HTML 4.0, che ci consentono di ridefinire la visualizzazione (ma solo quella) associata ai tag.
2.1.2 Fogli di stile in HTML
HTML 4.0 supporta il linguaggio CSS (Cascading Style Sheet) per i fogli di stile [5]. Questo linguaggio consente di definire la visualizzazione del contenuto dei vari tag di HTML senza utilizzare nuovi tag o attributi, ma associando delle norme di stile a ciascun tag. I fogli di stile possono essere sia contenuti all’interno del tag <STYLE> del documento HTML, che posti in file esterni.
Vediamo come si riesce a modificare la visualizzazione del tag <h1> per mezzo di alcune semplici norme di stile:
<h1 align=center>
Titolo Principale</h1><STYLE>
H1 {background:yellow; color: red; font-family: Arial; font-size: 20pt;}
</STYLE>
Il risultato che si ottiene è ben diverso da quanto visto nel paragrafo precedente:
2.1.3 Estensioni non ufficiali di HTML
HTML è un linguaggio chiuso e non modificabile. L'autore di un documento può soltanto scegliere tra un insieme prefissato di elementi, anche se la struttura del suo documento richiederebbe di esplicitarne altri, o di qualificarli in modo diverso [11].
Il W3C è l'unico ente che è in grado di aggiungere nuovi elementi ad HTML e, come abbiamo visto nel § 1.2.3, lo ha fatto diverse volte, portando HTML alla versione 4.01. In realtà, negli anni precedenti erano stati i produttori dei browser, Microsoft e Netscape, a sostituirsi al W3C, aggiungendo arbitrariamente vari elementi ad HTML e creando le cosiddette "estensioni non ufficiali" di HTML, che hanno messo in serio pericolo la standardizzazione dei documenti Web [7]. Queste estensioni non standardizzate del linguaggio hanno causato seri problemi come:
| documenti che per essere letti necessitavano di Explorer o di Netscape e che, nel caso fossero stati visualizzati in modo alternativo, risultavano diversi o addirittura illegibili; | |
| siti ottimizzati per alcune versioni di browser e non per altre; | |
| documenti che non erano accessibili con versioni precedenti dei browser. |
Il W3C ha cercato di porre rimedio a questa situazione inserendo i fogli di stile, una tecnica introdotta proprio da SGML e utilizzata, ovviamente, anche in XML [1].
Infine la struttura rigida e non estensibile di HTML si rivela un problema per le grandi industrie, che sono state costrette a:
2.2 HTML è orientato solo alla descrizione dei documenti
HTML fu creato come un linguaggio di descrizione del documento, che consentisse agli utenti di condividere le informazioni su sistemi differenti [5]. Il presupposto di HTML era che quelle informazioni fossero testo con in più alcune immagini e collegamenti ipertestuali. Attualmente, invece, nel Web si trova di tutto:
| database, | |
| suoni, | |
| filmati, | |
| programmi interattivi |
ed altro ancora. Un linguaggio nato sostanzialmente per la pubblicazione di documenti semplici si trovava a dover assicurare potenzialità impensabili al momento della sua nascita e così, non potendo, lasciava il campo allo sviluppo di tecnologie parallele che potessero assicurare la sua sopravvivenza e il supporto per i nuovi contenuti del Web [7].
Tra nuovi linguaggi tipo Javascript e plug-in tipo Shockwave o Acrobat reader, in pratica HTML è diventato pian piano un assemblatore di tecnologie piuttosto che un linguaggio vero e proprio e questo ha comportato anche problemi di portabilità delle applicazioni Web, poiché tutte queste nuove tecnologie non sono standard, bensì soluzioni proprietarie più o meno diffuse che necessitano per essere utilizzate di software specifici o di particolari versioni di esso. Tutto ciò è lontanissimo dalla filosofia iniziale ma anche dalla tendenza, tipica dell'informatica distribuita che in questo periodo si sta affermando, a costruire ambienti standard in grado di permettere lo sviluppo di applicazioni portabili a prescindere dall’hardware o dal sistema operativo.
HTML non è mai stato progettato per il controllo della formattazione e quindi manca dei meccanismi adatti: esso dovrebbe semplicemente fornire una descrizione del documento, dando così solo delle indicazioni generiche sulla formattazione, che resterebbe compito del browser, o del programma che deve visualizzare il file [5]. I tag aggiunti nel corso degli anni, specialmente quelli delle estensioni non ufficiali, erano dei veri e propri tag di formattazione. Ad esempio, nell’HTML originale esiste il tag <STRONG>
, che significa "molto evidenziato" [16]. Il testo in esso racchiuso viene in genere visualizzato in neretto, ma è un tag che dà indicazioni sull’importanza del suo contenuto, senza entrare esplicitamente nel merito della formattazione. Successivamente è stato introdotto il tag <B> (Bold = Neretto), il cui significato è evidentemente limitato rispetto al precedente. Alcuni di questi hanno avuto origine come tag proprietari di uno dei due principali produttori di browser (Microsoft e Netscape) e la loro diffusione nelle pagine Web è stata tale da "costringere" il consorzio W3 ad approvarli nelle successive versioni di HTML.Il W3C si rese conto che l’introduzione di una moltitudine di nuovi tag che rispondessero ad ogni possibile esigenza di formattazione era irreale e incoerente con i principi di HTML. Il primo vero strumento di formattazione per HTML è stato introdotto solo con la versione 4.0 ed è costituito dai fogli di stile, per i quali sono stati definiti due linguaggi specifici: CSS1 e CSS2. I fogli di stile sono separati dal codice HTML, così come gli script, e riescono ad ottenere la distinzione tra forma e struttura del documento. I linguaggi CSS1 e CSS2 sono molto semplici e sono adattabili anche all’XML, ma sono molto meno potenti di XSL, ideato appositamente per XML.
In conclusione, bisogna notare che finora i browser Web sono stati le principali piattaforme di sviluppo per il linguaggio Java. Per un’interazione migliore con Java, sarebbe opportuno un linguaggio più sofisticato e più orientato al trattamento dei dati di HTML, limitato alla descrizione dei testi [12].
2.3 HTML non consente visualizzazioni diverse dei documenti
È difficile scrivere del codice HTML che mostri gli stessi dati in modi differenti, a seconda delle esigenze dell’utente [10]. È ancora più difficile realizzare delle viste personalizzate di dati diversi dal testo, come ad esempio i risultati dell’interrogazione di una base di dati. Non è un caso che per la creazione di siti dinamici e in grado di interagire con dati, come per esempio un catalogo che permette ordinazioni, sia necessario l'uso di tecnologie esterne alle specifiche HTML, come le CGI, Javascript o addirittura Java [7].
Una possibile soluzione di questi problemi è nell’HTML dinamico (DHTML). DHTML non è un linguaggio di markup come HTML, ma semplicemente un insieme di regole che permettono di usare i fogli di stile e un linguaggio di script al fine di modificare l'aspetto ed il contenuto di una pagina Web al verificarsi di un dato evento (ad esempio il click o lo spostamento del mouse, o il trascorrere di un periodo di tempo) [11]. DHTML, però, ha dei notevoli difetti:
| richiede degli script lunghi e complicati; | |
| è un sistema orientato alla creazione di effetti visivi, piuttosto che alla formattazione dei dati. |
L’avvento di XML dovrebbe superare definitivamente questa ennesima estensione di HTML. Del resto è già possibile associare ad un solo documento HTML diversi fogli di stile, per adattare un unico contenuto a diversi tipi di presentazione, come quelle ottenute con:
| i normali browser grafici, | |
| i vecchi browser testuali, | |
| gli schermi televisivi, per i quali sono richiesti caratteri più visibili, | |
| i sistemi braille per non vedenti, | |
| i sistemi vocali per non udenti, | |
| ecc. |
È bene ricordare che la tecnologia dei fogli di stile viene da SGML ed è implementata anche in XML.
2.4 HTML non ha una struttura semantica
La maggior parte delle applicazioni Web trarrebbe beneficio dalla possibilità di catalogare i dati in base al loro significato, piuttosto che in modo descrittivo, come fa HTML [10]. Ad esempio, noi sappiamo che:
<h2>
Apple</h2>si presenterà in un certo modo in un browser, ma non sappiamo se Apple sia un frutto, l’azienda produttrice di computer, un cognome o qualcos’altro [12].
Una possibilità per specificare la semantica di un documento è data dal tag <META>, il quale [10]:
| è utilizzabile solo nell’intestazione del documento, quindi non si può associare a particolari dati significativi contenuti in esso; | |
| è uno dei tag meno usati di HTML. |
In questo modo, si perdono molte delle potenzialità dei motori di ricerca, costretti ad esaminare tutto il testo a parità di importanza, proprio nel momento in cui la mole dei documenti in rete diventa tale da richiedere un meccanismo più puntuale [7]. Purtroppo però l’assenza di tag semantici non permette questa possibilità e obbliga a ricerche che spesso restituiscono migliaia di documenti senza dire nulla del significato del termine invocato.
HTML non ha alcun modo di specificare che cosa significhi una certa stringa o un certo dato nella pagina Web [10]. Non solo: HTML non ha alcuno strumento di analisi di validità di un documento, cosa di fondamentale importanza per importare ed utilizzare un documento in altre applicazioni. Quest’esigenza, imprevedibile alla creazione del Web, è diventata di estrema necessità a causa delle nuove applicazioni che si servono di Internet, come ad esempio il commercio elettronico [15]. Viceversa XML:
2.5 Problemi nella conversione in HTML da altri formati
Molte organizzazioni pubblicano le stesse informazioni in diversi formati [14]. Accade di frequente, infatti, che esistano almeno due versioni di uno stesso documento:
basti pensare ai numerosi giornali che offrono una loro versione elettronica su Web. Solitamente la versione originale dei documenti viene scritta con un software specifico, ad esempio un word processor, e la traduzione in HTML viene effettuata automaticamente da opportuni programmi [10]. Purtoppo queste conversioni non sono sempre perfette e richiedono delle correzioni da effettuare manualmente, come è noto a chi ha provato l'opzione "salva come HTML" di Word. Ciò significa che al cambiare del documento originario bisogna ripetere tali aggiustamenti, con conseguente dispendio di energia e di tempo [14]. D’altra parte queste aziende non hanno alcun interesse a produrre documenti direttamente in HTML, poiché la pubblicazione su Web non è la loro attività principale.
La causa di questi problemi è nella scarsa flessibilità di HTML, che offre molti meno strumenti rispetto ai moderni word processor e ai programmi professionali per l’editoria, come Adobe Acrobat. Alcuni siti evitano il problema a priori lasciando sul Web i documenti in formato Acrobat e costringendo gli utenti ad avere l'apposito lettore.
XML è la soluzione ideale per questi problemi. Esistono delle potenti applicazioni per l'editoria elettronica basate su SGML che possono essere utilizzate senza difficoltà per XML, tra le quali citiamo FrameMaker, realizzato proprio dalla Adobe, l’azienda produttrice di Acrobat [1].
2.6 Problemi relativi ai link
2.6.1 HTML consente solo collegamenti semplici
HTML, attraverso il tag <A> (ancora), assicura la possibilità di saltare da un punto ad un altro del documento o dell’intero Web [7]. Questo elemento, però, utilizza solo la più semplice delle diverse tipologie di link: il link unidirezionale. Vediamo un esempio di link HTML:
<a href="
http://www.w3.org/">Consorzio WWW</a>Questo collegamento è unidirezionale, poiché sono definiti:
| l’origine, che è semplicemente il testo contenuto tra i tag di apertura e chiusura; | |
| la destinazione, che è il valore dell’attributo href. |
Non è possibile con il solo HTML percorrere a ritroso questo link, anche se è semplicissimo farlo utilizzando il tasto "indietro" del browser, oppure usando la funzione Javascript history.back()
[18].Sin dagli anni settanta, invece, è stata sviluppata una complessa tipologia di collegamenti ipertestuali, che corrispondono a diverse relazioni semantiche [11]:
| link bidirezionali; | |
| link con destinazioni e origini multiple (uno a molti e molti a uno); | |
| link che puntano su sezioni strutturali di un documento di destinazione; | |
| link in grado di incorporare la destinazione nel documento sorgente; | |
| link definiti in un documento esterno a quello di partenza; | |
| link a scelta multipla |
ed altro ancora. Alcune di queste possibilità sono già state realizzate grazie all’apporto di Java. Di per sé, HTML consente solo di aprire la risorsa destinazione di un collegamento all’interno del documento di origine con la tecnica dei frame, che presenta vari problemi [5]:
| le pagine con diversi frame sono incomprensibili a bassa risoluzione; | |
| se la connessione a Internet è lenta, la pagina con i frame richiede un lungo tempo di caricamento; | |
| talvolta, per degli errori nella trasmissione dei dati, non tutti i frame vengono caricati e la pagina è inutilizzabile. |
XML, tramite i suoi linguaggi XLink ed XPointer, supporta pienamente tutti questi tipi di collegamento. XPointer, in particolare, riesce ad indirizzare qualsiasi parte di un documento, rappresentando gli elementi del documento all’interno di una struttura ad albero, così come i moderni file system fanno con le directory ed i file (vedi § 7.5).
2.6.2 I link scomparsi
Una delle esperienze più comuni tra coloro che utilizzano abitualmente il World Wide Web è l’apparizione del messaggio :"HTTP/1.0: 404 Oggetto non trovato", quando si cerca di accedere a un documento attraverso un link ipertestuale o mediante il suo URL (Uniform Resource Locator) [11]. Ciò significa semplicemente che il file corrispondente non si trova più nella posizione indicata dal suo indirizzo, poiché è stato spostato, cancellato o rinominato.
In questo caso non si tratta di una scelta dello standard, quanto piuttosto di un "effetto collaterale" della struttura sintattica dell’elemento <A> in HTML [7]. Infatti l’indirizzo della risorsa di destinazione viene riportato esplicitamente nel documento HTML come valore dell’attributo HREF, e non in un database o in un altro documento, generando notevoli problemi di manutenzione. In caso di cancellazione della risorsa di destinazione o anche di semplice modifica del suo path, diventa allora necessario modificare tutti i documenti che a quella risorsa avevano un riferimento, se si vuole evitare di lasciare in circolazione testi contenenti link scomparsi. Questo problema si può arginare solamente utilizzando nei documenti dei semplici identificativi contenuti fuori dal documento stesso, in archivi che, modificati in seguito ad un cambiamento dell’indirizzo della risorsa, aggiornano immediatamente tutti i collegamenti.
Per rispondere a questa esigenza, vari enti ed organizzazioni che si occupano dello sviluppo degli standard su Internet hanno proposto una architettura ad hoc denominata Uniform Resource Name (URN) [11]. In realtà con questa sigla viene indicata una serie di tecnologie, ancora in fase sperimentale, nate in ambiti diversi e caratterizzate da diversi approcci e finalità immediate.
Un URN è un identificatore che può essere associato ad ogni risorsa disponibile su Internet, e che dovrebbe essere utilizzato in tutti i contesti che attualmente fanno uso degli URL. In generale, esso gode delle seguenti caratteristiche:
| unicità: due risorse distinte non possono avere lo stesso URN; | |
| validità globale: un URN è indipendente dalla localizzazione della risorsa; | |
| persistenza: una volta assegnato un URN ad una risorsa esso rimarrà associato ad essa per sempre, anche se la risorsa non sarà più disponibile; nessuna altra risorsa in futuro potrà avere un URN già assegnato; | |
| scalabilità: ogni tipo di risorsa su Internet, presente e futura, potrà avere un URN che gode delle caratteristiche elencate sopra. |
Ciascuna risorsa individuata da un URN può essere disponibile in molteplici copie, distribuite su diversi luoghi della rete: conseguentemente ad ogni URN possono corrispondere molteplici URL.
Attualmente le risorse dotate di URN sono poche, ma tra queste vi sono gli spazi dei nomi di cui fanno uso alcune applicazioni XML. Un esempio di URN è il seguente:
urn:schemas-microsoft-com:xml-data
ed è l’URN che contiene lo spazio dei nomi di XML-Data. Torneremo nei §§ 4.6 e 4.7 sia sugli spazi dei nomi che su XML-Data.
2.7 HTML si sta evolvendo anche troppo rapidamente
Come abbiamo visto, HTML è uno standard in continua evoluzione [14]. Finora le sue capacità sono state continuamente estese attraverso l’introduzione di nuovi tag. Per le organizzazioni che gestiscono grandi quantità di informazioni in HTML, il rilascio di nuove versioni di questo linguaggio provoca in genere notevoli problemi di manutenzione dei documenti esistenti, non tanto perché venga meno la compatibilità nei confronti delle versioni precedenti, quanto per la necessità di offrire pagine Web sempre "al passo con i tempi" e quindi in grado di sfoggiare le novità portate dall’ultima versione di HTML.
Recentemente Microsoft e Netscape hanno aumentato l’intervallo di tempo fra i rilasci di una versione e della successiva dei loro browser, portandola da sei mesi a circa un anno. Molti webmaster malignamente pensano che ciò sia dovuto al tempo impiegato da queste due software house per aggiornare i loro enormi siti, al fine di ottimizzarli per la navigazione con il rispettivo nuovo browser, operazione che forse richiede più tempo dello sviluppo del browser stesso.
Per evitare completamente questo problema, molte grandi organizzazioni già da tempo scrivono i propri documenti in formato SGML, effettuando automaticamente la traduzione in HTML con appositi programmi. L’aggiornamento di un traduttore di questo tipo per una nuova versione di HTML richiede un tempo enormemente inferiore rispetto alla ricostruzione di tutti i documenti di interi siti.
L’avvento di XML, che è una semplificazione di SGML, agevola enormemente coloro che vogliono pubblicare su Web i propri documenti SGML. Molti affermati prodotti software per comporre documenti SGML supportano già l’esportazione in formato XML [5]. La possibilità di usare XML direttamente su Web permette di confinare i tag presenti e futuri di HTML ai soli fogli di stile: eventuali aggiornamenti di HTML si ripercuoteranno solo sulla presentazione su Web del documento, lasciando inalterata la sua versione in XML.
2.8 Conclusioni
Finora abbiamo evidenziato solamente i limiti e i difetti di HTML, notando come XML sia in grado di superarli. Potrebbe sembrare così che XML debba sostituire completamente HTML, ma ciò non è assolutamente necessario. HTML ha numerosi punti a suo vantaggio, i più importanti dei quali sono [17]:
| ha una struttura molto semplice, che consente di progettare e realizzare rapidamente i documenti; | |
| è molto veloce e quindi adatto per le applicazioni su Web; | |
| può essere visualizzato su qualsiasi computer, indipendentemente dall’hardware e dal sistema operativo; | |
| è supportato da moltissimi programmi: persino i word processor più recenti esportano in formato HTML; | |
| non necessita di validazione. |
Per le applicazioni più semplici del Web passare all’XML potrebbe risultare addirittura uno svantaggio. Esistono numerosissime pagine Web che:
| non contengono dati strutturati o con un particolare significato; | |
| non hanno interesse a comparire nei motori di ricerca; | |
| non hanno bisogno di collegamenti estesi o multidirezionali. |
Quasi sicuramente il linguaggio di queste pagine resterà HTML. Del resto se io ho una homepage personale visitata al più da qualche mio amico, chi me lo fa fare a:
Al termine di questo lavoro avrei lo svantaggio che i miei amici con browser vecchi non riuscirebbero neanche più ad accedere alla pagina.
In realtà HTML ed XML sono complementari tra loro e trattano i dati su livelli differenti [19]:
| XML è usato per strutturare e descrivere i dati; | |
| HTML è usato per visualizzarli sul Web. |
Infatti XSL, che si occupa della rappresentazione dei dati, prevede la possibilità di utilizzare tag di HTML. La cosa non è indispensabile, visto che si potrebbero usare anche dei tag propri di XSL, chiamati oggetti di formattazione, ma è molto utile, poiché i tag di HTML sono molto più conosciuti e semplici da usare (vedi § 5.9). Si può concludere che:
| se HTML soddisfa le proprie esigenze, non c’è alcuna necessità di passare ad XML. | |
| Se HTML è ritenuto insufficiente, si possono superare i suoi limiti: |
3 STRUTTURA E SINTASSI DI XML
3.1 Il processo di codifica XML
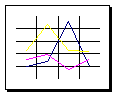
Il seguente diagramma illustra i componenti fondamentali di un documento XML completo e come questi interagiscano fra loro [5]:
![]()
![]()
Questo schema non è l’unico possibile, in quanto:
È appena il caso di notare che i file XML, DTD ed XSL possono trovarsi nello stesso computer, così come in tre continenti diversi: questa è una caratteristica di tutte le tecnologie correlate ad Internet.
In questo capitolo ci occuperemo esclusivamente della composizione dei documenti XML. Il capitolo 4 sarà dedicato alle DTD e i capitoli 5 e 6 al linguaggio XSL.
3.2 La sintassi di XML
3.2.1 Sintassi dei tag
In XML viene definito elemento:
| tutto ciò che è racchiuso tra un tag di apertura ed un tag di chiusura: |
| l’elemento vuoto, che non ha contenuto ed ha una sintassi leggermente diversa: |
Riassumiamo le sintassi dei due tipi di elementi per mezzo di questo schema [10]:
<Nome attributo="
valore"></Nome>
<Vuoto attributo="valore"/>Ogni attributo associa ad un elemento un valore, il quale è un’informazione che non fa parte del contenuto dell’elemento stesso. Come in HTML, gli attributi possono essere un numero qualsiasi, eventualmente anche nessuno. Se gli attributi sono più di uno, le coppie formate da attributo e valore vengono semplicemente elencate all’interno del tag di apertura o del tag di elemento vuoto:
<Nome attributo1="
valore1" attributo2="valore2">Contenuto</Nome>3.2.2 Obblighi sintattici imposti da XML
Apparentemente la sintassi di XML è la stessa di HTML. Ci sono, invece, alcune differenze di fondamentale importanza.
Nome
¹ NOME ¹ nome ¹ NoMe<ESTERNO>
<INTERNO>
Contenuto</INTERNO></ESTERNO>
mentre è sbagliata:
<ESTERNO>
<INTERNO>
Contenuto</ESTERNO> NO!</INTERNO>
3.3 Documenti validi e ben formati
HTML definisce un insieme di elementi, ciascuno con un proprio significato ed un proprio effetto sulla visualizzazione del documento. XML non detta regole di questo tipo, ma lascia due possibilità:
Come in tutti i linguaggi, anche in XML esistono delle parole riservate che non possono essere utilizzate liberamente come nomi di elementi, attributi o per markup di altro tipo [5]. Secondo la specifica XML del W3C, sono parole riservate le stringhe:
XML, xml, Xml, xML, …
e tutte le altre possibili combinazioni con lettere maiuscole e minuscole [6]. Nessun nome può iniziare con una di queste stringhe, o essere uguale ad una di esse [1].
Per il resto la scelta dei nomi è molto flessibile, in quanto:
| i nomi possono iniziare con una qualsiasi lettera maiuscola o minuscola; | |
| possono contenere una qualsiasi sequenza di lettere maiuscole, minuscole e cifre. Sono ammessi anche i caratteri: ".", "-" e "_"; | |
| il carattere ":" è ammesso, ma può essere utilizzato solo per dichiarare l’appartenenza ad uno spazio dei nomi (vedi § 4.6). |
Ricordiamo che un documento scritto con un linguaggio di markup è composto dal testo e dal markup.
Mentre il markup segue delle regole sintattiche precise, il testo deve poter contenere qualsiasi carattere. In XML, però, alcuni caratteri non dovrebbero essere inseriti direttamente nel testo, poiché possono confondersi con il markup. Essi sono:
< > & ' "
XML consente di sostituire questi caratteri con entità predefinite. Vedremo in seguito come è possibile far riferimento a tali entità e quindi utilizzare anche questi caratteri nel testo.
3.4 Prologo
I documenti XML possono cominciare con un prologo, il quale è composto da:
| una dichiarazione XML, | |
| una dichiarazione di tipo di documento |
entrambe facoltative.
3.4.1 Dichiarazione XML
La dichiarazione XML è composta da 3 parti:
<?xml version="1.0"?>
Per il momento l’unica versione di XML è la 1.0, dunque l’unico valore possibile per il numero di versione è "1.0". Si noti inoltre che la stringa "xml" deve essere scritta in lettere minuscole.
<?xml version="1.0" encoding="UTF-8" ?>
Alcune possibili codifiche sono rappresentate dalle seguenti stringhe [6]:

UTF-8: Unicode ad 8 bit (è la codifica normalmente utilizzata); UTF-16: Unicode a 16 bit (è una codifica comprendente 65.536 caratteri non supportata da tutti i sistemi operativi); EUC-JP: caratteri giapponesi.
- Dichiarazione di documento indipendente. Consente di specificare se debba essere recuperata o meno la parte esterna della DTD per analizzare correttamente la validità del documento [1]. La sintassi è:
<?xml version="1.0" standalone='yes'?>
dove:
standalone='yes': il documento è indipendente e non vanno considerate eventuali DTD o parti di DTD esterne ad esso; standalone='no': il documento dipende dalla parte esterna della DTD.
Se non vi sono DTD o parti di DTD esterne al documento, questa dichiarazione non ha senso [6]. Se è presente un riferimento ad una DTD esterna, il valore "no" è assunto come default.
3.4.2 Dichiarazione di tipo di documento
La dichiarazione di tipo di documento, se presente, stabilisce la conformità del documento ad una certa DTD. Le possibili sintassi sono due:
- DTD interna al documento:
<!DOCTYPE RADICE [DTD]>
supponendo che RADICE sia il nome dell’elemento radice del documento. Ciò significa che nell’associazione alla DTD, il documento XML viene identificato per mezzo del nome del suo elemento radice. Tra le parentesi quadre va scritta per esteso la DTD del documento. Tratteremo la composizione delle DTD nel prossimo capitolo.
- DTD in un file esterno al documento [19]:
<!DOCTYPE RADICE SYSTEM "
documento.dtd">
"documento.dtd" è il file dove si trova la DTD del documento. La parola chiave SYSTEM indica che il nome del file è un identificatore di sistema. Ovviamente tale nome può essere anche un indirizzo Internet [1]:
<!DOCTYPE RADICE SYSTEM "
http://www.inform.unian.it/documento.dtd">
Infine c’è la possibilità che la DTD abbia un identificatore pubblico, che consente al software di utilizzare una propria copia della DTD oppure di reperire questa su determinati server veloci di sua conoscenza. In questo caso è utilizzata la parola chiave PUBLIC:
<!DOCTYPE RADICE PUBLIC "
-//SGMLSOURCE//DTD MEMO//EN"
"http://www.sgmlsource.com/dtds/memo.dtd">
L’indirizzo Internet compare ugulamente e viene utilizzato nel caso il software non riesca ad interpretare l’identificatore pubblico.
Un documento XML può anche avere la sua DTD, che è unica per definizione, divisa in un sottoinsieme interno ed un sottoinsieme esterno [19]. In questo caso la sintassi è:
<!DOCTYPE RADICE SYSTEM "
esterna.dtd" [Sottoinsieme_interno_DTD]>
Se ci sono conflitti tra i due sottoinsiemi, viene data priorità al sottoinsieme interno della DTD, ignorando eventuali dichiarazioni esterne in contrasto con quelle all’interno del documento. In questo modo chi scrive un documento XML ha la possibilità di modificare una DTD esterna, senza che debba riscriverla completamente.
3.5 Entità predefinite
Il linguaggio XML prevede cinque entità predefinite, che possono sostituire i cinque caratteri che non andrebbero utilizzati all’interno del testo di un documento (<,>,&,',") [1]. Esse sono:
ENTITÀ
CARATTERE
&
&
<
<
>
>
'
‘
"
"
Vediamo un esempio:
<ESEMPIO>
<Titolo>
Come inserire del codice HTML in un documento XML
</Titolo>
<Codice>
<HTML> <HEAD> <TITLE>Titolo</TITLE> </HEAD> <BODY>Contenuto</BODY></HTML>
</Codice>
</ESEMPIO>
Per rendersi conto della sostituzione delle entità predefinite con i corrispondenti caratteri, ecco come Explorer 5 mostra questo documento XML:
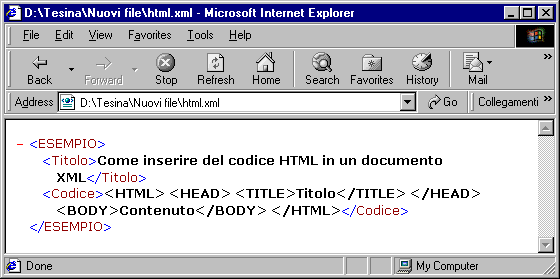
Si noti la distinzione tra il markup, che è colorato, ed il testo del documento, mostrato in nero. Tutti i tag del codice HTML sono in nero, dunque sono considerati come semplice testo e non analizzati come elementi di XML.
La sostituzione dei caratteri <,>,&,' e " con le entità predefinite non è obbligatoria, ma diventa necessaria nel caso siano possibili confusioni tra markup e testo, come nell’esempio precedente. È una buona norma usare comunque le entità predefinite, poiché il comportamento dei vari programmi alla presenza dei caratteri <,>,&,' e " nel testo può essere imprevedibile.
La sintassi delle entità predefinite:
&nome;
dove "nome" è il nome dell’entità, viene utilizzata in XML per i riferimenti alle entità generali. Le entità, ad eccezione delle cinque entità predefinite, devono essere dichiarate nella DTD, quindi verranno discusse nel prossimo capitolo.
3.6 Riferimenti ai caratteri
I documenti XML sono costituiti esclusivamente da caratteri con codice ASCII dal 32 al 127. Per inserire in un documento XML caratteri con codice ASCII superiore al 127, esistono due possibilità:
Il riferimento numerico ha la seguente sintassi:
&#Codice;
dove Codice è il numero di codice del carattere secondo la codifica utilizzata. È possibile anche scrivere questo numero in esadecimale, utilizzando la sintassi:
odice_hex;
Vediamo un piccolo esempio:
<ESEMPIO>
</ESEMPIO>
e come viene visualizzato da Explorer 5:
<
ESEMPIO>In XML si può far riferimento a caratteri speciali utilizzando le ENTITÀ oppure i RIFERIMENTI NUMERICI.</ESEMPIO>L’elenco completo dei codici dei caratteri nella codifica UTF-8 si può trovare in [5] o in qualsiasi manuale di HTML.
3.7 Istruzioni di elaborazione
Le istruzioni di elaborazione, dette anche PI (Processing Instructions) forniscono indicazioni al programma che elabora il documento XML [19]. Queste istruzioni sono normalmente posizionate nel prologo, ma possono comparire in un punto qualsiasi del documento. La sintassi è questa:
<?Istruzione?>
dove "Istruzione " dipende dal software che utilizza il file XML. Ad esempio, l’istruzione di elaborazione:
<?xml-stylesheet type="text/xsl" href="
documento.xsl"?>indica che il documento XML deve essere visualizzato per mezzo del foglio di stile XSL nel file "documento.xsl". Il W3C ha standardizzato le istruzioni di elaborazione per l’associazione dei fogli di stile ai documenti XML con una raccomandazione del giugno 1999 [20].
Un altro esempio di istruzione di elaborazione è [19]:
<?AVI CODEC="VIDEO1" COLORS="256"?>
che fornisce indicazioni al browser sulla riproduzione dei filmati in formato AVI.
Formalmente, anche la dichiarazione XML è un’istruzione di elaborazione, visto che segue la stessa sintassi delle PI:
<?xml version="1.0"?>
3.8 Commenti
I commenti in XML sono aperti dalla sequenza di caratteri "<!--" e chiusi dalla sequenza "-->" [1]. Possono contenere qualsiasi stringa, ad eccezione della coppia di caratteri "--". Esempio:
<!--
Commento-->All’interno dei commenti possono essere utilizzati direttamente i cinque caratteri <,>,&,' e ", senza bisogno di ricorrere alle entità predefinite, dato che gli elaboratori XML non analizzano il contenuto dei commenti alla ricerca di markup:
<!--
Questo e' un commento con un numero di caratteri <100-->Per lo stesso motivo non è possibile inserire i caratteri con codice ASCII maggiore di 127, neanche utilizzando i riferimenti numerici o le entità. Infatti, nell’esempio precedente abbiamo sostituito il carattere "è" con la stringa "e’".
Consideriamo un breve documento HTML, che contiene l’elenco dei docenti di un dipartimento di informatica, con delle sommarie informazioni su ciascuno di essi:
<HTML>
<HEAD>
<TITLE>
Università di QualchePosto - Docenti del dipartimento di Informatica </TITLE></HEAD>
<BODY>
<FONT COLOR="#0000ff"><H1 ALIGN=CENTER>Università degli studi di QualchePosto</H1>
<H2 ALIGN="CENTER">Dipartimento di Informatica</H2>
</FONT><I><FONT COLOR="#ff00ff"><H3 ALIGN=CENTER>Elenco dei docenti</H3>
</I></FONT><B><P>
<FONT COLOR="#ff0000"><P>Gianni Brahms</B> : Professore Ordinario
</FONT><P>Gruppo di ricerca: <I>Intelligenza Artificiale</I>
<P>Curriculum vitae: Nato nel 1936 e laureato nel 1961. Dal 1974 è titolare della cattedra di Intelligenza Artificiale. Dirige il Dipartimento dal 1996.
<P>Elenco pubblicazioni:
<UL>
<LI>Uso delle variabili semantiche nella logica fuzzy (1986)
<LI>Regole di produzione ed EBNF (1988)
<LI>Utilizzo della logica fuzzy in problemi di scheduling della CPU (1991)
<LI>Tecniche di I.A. per i motori di ricerca (1997) </UL>
<P>
<HR>
<B><FONT COLOR="#ff0000"><P>Ermanno Grieg</B> : Professore Associato
</FONT><P>Gruppo di ricerca: <I>Reti Neurali</I>
<P>Curriculum vitae: Nato nel 1949 e laureato nel 1973. Dal 1978 è titolare della cattedra di Algoritmi per il controllo dei segnali.
<P>Elenco pubblicazioni:
<UL>
<LI>L'importanza dell'apprendimento nei percettroni multistrato (1980)
<LI>Reti neurali autoorganizzantisi: un approccio statistico (1986)
<LI>Simulazioni al Matlab di reti neurali non lineari (1991) </UL>
<HR>
<B><FONT COLOR="#ff0000"><P>Federico Mendelzon</B> :
</FONT><P>Gruppo di ricerca: <I>Visione delle macchine</I>
<P>Curriculum vitae: Nato nel 1971 e laureato nel 1998. Collabora con il prof. Brahms nel corso di Intelligenza artificiale.
<P>Elenco pubblicazioni:
<UL>
<LI>Progetto di un software in grado di riconoscere i tombini (1999)</UL>
<HR>
<B><FONT COLOR="#ff0000"><P>Riccardo Strauss</B> :
</FONT><P>Gruppo di ricerca: <I>Basi di Dati</I>
<P>Curriculum vitae: Nato nel 1968 e laureato nel 1996. Collabora con il prof. Verdi nel corso di Basi di dati.
<P>Elenco pubblicazioni:
<UL>
<LI>Modello Reticolare nei database orientati agli oggetti (1997) </UL>
<HR>
<B><FONT COLOR="#ff0000"><P>Giuseppe Verdi</B> : Professore Associato
</FONT><P>Gruppo di ricerca: <I>Basi di Dati</I>
<P>Curriculum vitae: Nato nel 1945 e laureato nel 1970. Nel 1984 ha ottenuto la cattedra di Basi di dati.
<P>Elenco pubblicazioni:
<UL>
<LI>Utilizzo di Oracle per l'amministrazione di piccole aziende (1991)
<LI>Come convertire un database gerarchico in un database relazionale (1994)
<LI>XML e le basi di dati su Internet (1998) </UL>
<HR>
<B><FONT COLOR="#ff0000"><P>Sebastiano Bach</B> : Professore Associato
</FONT><P>Gruppo di ricerca: <I>Ricerca Operativa
</I><P>Curriculum vitae: Nato nel 1941 e laureato nel 1970. Dal 1986 è il titolare della cattedra di Ricerca operativa.
<P>Elenco pubblicazioni:
<UL>
<LI>L'euristica per problemi di previsioni di mercato (1993)
<LI>Un problema di sfrido a 3 dimensioni (1995)
<LI>Una proposta per la composizione automatizzata degli orari ferroviari (1998) </UL>
</BODY>
</HTML>
La trasformazione del documento da HTML ad XML ben formato si può ricondurre fondamentalmente a quattro operazioni:
La trasformazione di un documento HTML in uno XHTML (e quindi XML) è effettuata automaticamente da alcuni software, tra cui il browser Amaya del W3C [22]. Vediamo un esempio di questa conversione. Il codice HTML:
<P>
Curriculum vitae: Nato nel 1968 e laureato nel 1996. Collabora con il prof. Verdi nel corso di Basi di dati.<P>Elenco pubblicazioni:
<UL>
<LI>Modello Reticolare nei database orientati agli oggetti (1997) </UL>
<HR>
in cui gli elementi <P> e <LI> non hanno il tag di chiusura e l’elemento <HR> non segue la sintassi di XML per gli elementi vuoti, diventa:
<p>
Curriculum vitae: Nato nel 1968 e laureato nel 1996. Collabora con il prof. Verdi nel corso di Basi di dati.</p><p>Elenco pubblicazioni:</p>
<ul>
<li>Modello Reticolare nei database orientati agli oggetti (1997)</li> </ul>
<hr/>
Si noti che l’XHTML impone l’uso delle lettere minuscole per tutti i tag di HTML, rispettando la case-sensitivity di XML.
Occorre inoltre sopprimere:
| alcuni elementi ed attributi di formattazione privi di qualsiasi semantica, | |
| alcune parti del testo ripetute di frequente. |
|
HTML |
XML |
|
|
<html> |
à |
soppresso |
|
<head> |
à |
<?xml version="1.0" encoding="UTF-8"?> |
|
<title> |
à |
soppresso |
|
<body> …</body> |
à |
<DOCENTI> …</DOCENTI> |
|
<font color="#0000ff"> |
à |
soppresso |
|
<h1> , <h2>, <h3> |
à |
soppressi |
|
<font color="#ff00ff"> |
à |
soppresso |
|
<font color="#ff0000"> |
à |
<PERSONA> |
|
<p><b>nome</b> |
à |
<NOME>nome</NOME> |
|
:titolo_accademico</p> |
à |
<TITOLO>titolo_accademico</TITOLO> |
|
Gruppo di ricerca: <i>…</i> |
à |
<GRUPPO> …</GRUPPO> |
|
<p> Curriculum vitae: …</p> |
à |
<CURRICULUM> …</CURRICULUM> |
|
<p> Elenco pubblicazioni:</p> |
à |
soppresso |
|
<ul> …</ul> |
à |
<PUBBLICAZIONI> …</PUBBLICAZIONI> |
|
<li> …</li> |
à |
<PUBBLICAZIONE> …</PUBBLICAZIONE> |
|
<hr/> |
à |
</PERSONA> |
|
HTML |
XML |
|
|
è |
à |
è |
|
HTML |
XML |
|
|
‘ |
à |
' |
Al termine di queste trasformazioni abbiamo il seguente documento XML ben formato:
<?xml version="1.0" encoding="UTF-8" ?>
<DOCENTI>
<PERSONA>
<NOME>
Gianni Brahms</NOME><GRUPPO>Intelligenza Artificiale</GRUPPO>
<TITOLO>Professore Ordinario</TITOLO>
<PUBBLICAZIONI>
<PUBBLICAZIONE>Uso delle variabili semantiche nella logica fuzzy
(1986)</PUBBLICAZIONE>
<PUBBLICAZIONE>Regole di produzione ed EBNF (1988)</PUBBLICAZIONE>
<PUBBLICAZIONE>Utilizzo della logica fuzzy in problemi di scheduling
</PUBBLICAZIONI>
</PERSONA>
<PERSONA>
<NOME>Ermanno Grieg</NOME>
<GRUPPO>Reti Neurali</GRUPPO>
<TITOLO>Professore Associato</TITOLO>
<PUBBLICAZIONI>
<PUBBLICAZIONE>L'importanza dell'apprendimento nei
<PUBBLICAZIONE>Reti neurali autoorganizzantisi: un approccio
</PUBBLICAZIONI>
<CURRICULUM>Nato nel 1949 e laureato nel 1973. Dal 1978 è
titolare della cattedra di Algoritmi per il controllo dei
segnali.</CURRICULUM>
</PERSONA>
<PERSONA>
<NOME>Federico Mendelzon</NOME>
<GRUPPO>Visione delle macchine</GRUPPO>
<PUBBLICAZIONI>
</PUBBLICAZIONI>
<CURRICULUM>Nato nel 1971 e laureato nel 1998. Collabora con il prof.
Brahms nel corso di Intelligenza artificiale.</CURRICULUM>
</PERSONA>
<PERSONA>
<NOME>Riccardo Strauss</NOME>
<GRUPPO>Basi di Dati</GRUPPO>
<PUBBLICAZIONI>
<PUBBLICAZIONE>Modello Reticolare nei database orientati agli
</PUBBLICAZIONI>
<CURRICULUM>Nato nel 1968 e laureato nel 1996. Collabora con il prof.
Verdi nel corso di Basi di dati.</CURRICULUM>
</PERSONA>
<PERSONA>
<NOME>Giuseppe Verdi</NOME>
<GRUPPO>Basi di Dati</GRUPPO>
<TITOLO>Professore Associato</TITOLO>
<PUBBLICAZIONI>
<PUBBLICAZIONE>Utilizzo di Oracle per l'amministrazione di
<PUBBLICAZIONE>Come convertire un database gerarchico in un database
</PUBBLICAZIONI>
<CURRICULUM>Nato nel 1945 e laureato nel 1970. Nel 1984 ha ottenuto la
cattedra di Basi di dati.</CURRICULUM>
</PERSONA>
<PERSONA>
<NOME>Sebastiano Bach</NOME>
<GRUPPO>Ricerca Operativa</GRUPPO>
<TITOLO>Professore Associato</TITOLO>
<PUBBLICAZIONI>
<PUBBLICAZIONE>L'euristica per problemi di previsioni di
</PUBBLICAZIONI>
</PERSONA>
</DOCENTI>
Questo documento ha una precisa struttura ad albero, che si può già intuire dalle diverse indentature dei vari elementi nel listato. Mostriamo più in dettaglio questa struttura, servendoci della rappresentazione grafica fornita dal programma XML Notepad della Microsoft:
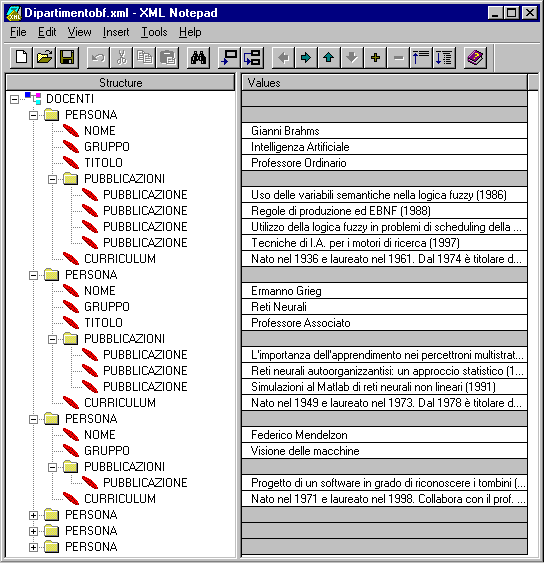
Per motivi di spazio sono stati completamente espansi solo i rami relativi a tre dei sei elementi PERSONA. Vediamo, infine, la struttura ad albero utilizzando un grafo "tradizionale":
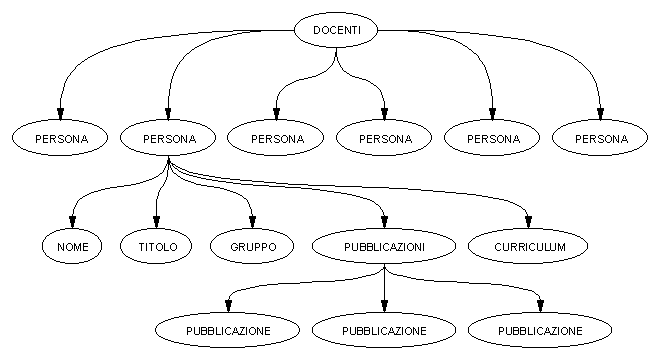
In questo caso, per motivi di spazio, abbiamo espanso solamente il ramo relativo al secondo elemento PERSONA (Ermanno Grieg).
4 DOCUMENT TYPE DEFINITION (DTD)
4.1 Dichiarazione degli elementi
La DTD di un documento definisce gli elementi, gli attributi e le entità consentiti al suo interno. Inoltre essa esprime come questi debbano essere combinati, affinché il documento sia valido [1].
La sintassi per la dichiarazione di un elemento NOME in un documento XML è:
<!ELEMENT NOME CONTENUTO>
dove CONTENUTO può avere i seguenti valori:
|
Valore di CONTENUTO |
Contenuto consentito |
|
EMPTY |
Nessuno. L’elemento dev’essere vuoto e seguire la sintassi per gli elementi vuoti. |
|
ANY |
Qualsiasi. L’elemento può contenere qualunque combinazione di sottoelementi e testo. |
|
(FIGLIO) |
L’elemento può contenere solo un sottoelemento di nome FIGLIO. Il nome del sottoelemento deve essere racchiuso fra parentesi tonde. |
|
(#PCDATA) |
L’elemento può contenere solo una stringa di testo di qualsiasi lunghezza o, eventualmente, essere vuoto. Anche in questo caso sono obbligatorie le parentesi. |
Il contenuto di un elemento può essere specificato con precisione utilizzando degli operatori che consentono di combinare le possibilità appena elencate [19]. Per chiarire l’uso di questi operatori, supponiamo che A e B siano sottoelementi. Si ha:
|
Operatore |
Valore di CONTENUTO |
Contenuto consentito |
|
| |
(A|B) (#PCDATA|A) |
L’elemento deve contenere uno solo tra A e B, senza ripetizioni. L’elemento può contenere una stringa di testo oppure un solo sottoelemento A. |
|
, |
(A,B) |
L’elemento deve contenere prima A e poi B, per una sola volta e nell’ordine specificato. |
|
? |
(A?) |
L’elemento può contenere A o essere vuoto. Non sono ammesse ripetizioni di A. |
|
* |
(A*) |
L’elemento può contenere un numero qualsiasi di occorrenze di A o essere vuoto. |
|
+ |
(A+) |
L’elemento deve contenere A, che può essere ripetuto per un numero qualsiasi di volte. |
È formalmente possibile usare gli operatori ?
, * e + anche con la parola chiave #PCDATA, anche se non hanno alcun effetto su essa.Gli operatori possono essere combinati in vari modi, utilizzando anche parentesi multiple. È importante che la parola chiave #PCDATA, se utilizzata, sia posta all’inizio di CONTENUTO [5].
4.1.1 Esempi di dichiarazione degli elementi
Esempio 1. Per evidenziare meglio la collocazione della DTD all’interno di un documento XML, analizziamo il seguente documento XML valido, che realizza l’esempio di e-mail del §1.1 [19]:
<?xml version="1.0"?>
<!DOCTYPE EMAIL [
<!ELEMENT EMAIL (A,DA,CC,TITOLO,TESTO)>
<!ELEMENT A (#PCDATA)>
<!ELEMENT DA (#PCDATA)>
<!ELEMENT CC (#PCDATA)>
<!ELEMENT TITOLO (#PCDATA)>
<!ELEMENT TESTO (#PCDATA)>
]>
<EMAIL>
<A>
Alessandro</A><DA>Luca</DA>
<CC>Ezio</CC>
<TITOLO>Prova</TITOLO>
<TESTO>
</EMAIL>
Abbiamo diviso il documento in definizione (DTD) e istanza, seguendo la terminologia delle basi di dati [3]. In XML il documento coincide con l’istanza, mentre la definizione, se presente, è separata dalla struttura ad albero del documento, essendo racchiusa all’interno del prologo (vedi
§ 3.4.2).
Affinché il documento sia valido, l’istanza deve seguire le regole dettate dalla definizione. Nel nostro esempio, l’elemento radice del documento è EMAIL, che contiene nell’ordine i cinque sottoelementi A, DA, CC, TITOLO e TESTO. Questi a loro volta contengono solo testo.
La DTD presentata è estremamente rigida: i cinque sottoelementi devono comparire tutti, essere nell’ordine stabilito e contenere testo. Una possibile variazione della DTD più conforme alla realtà si può ottenere introducendo alcuni operatori nella dichiarazione della radice [19]:
<!ELEMENT EMAIL (A+,DA,CC*,TITOLO?,TESTO?)>
in questo modo:
| l’elemento A è obbligatorio e può essere ripetuto più di una volta; | |
| l’elemento CC può o non comparire, o essere presente una o più volte; | |
| gli elementi TITOLO e TESTO sono facoltativi, ma se presenti non possono essere ripetuti; | |
| l’ordine degli elementi rimane fissato: se ci sono più elementi A, DA deve trovarsi dopo l’ultimo di questi e così via. |
Esempio 2.
<!ELEMENT paragrafo (#PCDATA|grassetto|corsivo)*>
L’elemento paragrafo
può contenere stringhe di testo e degli elementi grassetto e corsivo, in qualsiasi numero ed in qualsiasi ordine [1]. Eventualmente l’elemento può anche essere vuoto. Per evitare questa possibilità basta sostituire l’operatore + all’operatore *.Come abbiamo detto, #PCDATA, se presente, deve trovarsi all’inizio della stringa che definisce il contenuto dell’elemento. Ciò significa che la dichiarazione:
<!ELEMENT paragrafo (grassetto|corsivo|#PCDATA)*>
NO!sarebbe scorretta, mentre risulta corretta quella precedente.
Esempio 3. È possibile utilizzare più coppie di parentesi. Esse assumono lo stesso valore che hanno nelle espressioni matematiche:
<!ELEMENT FAQ (INTRODUZIONE,(DOMANDA,RISPOSTA)+,COPYRIGHT?)>
L’elemento FAQ deve contenere:
Esempio 4. Chiudiamo con una dichiarazione di elemento vuoto:
<!ELEMENT VUOTO EMPTY>
Per inserire un elemento opzionale non si può usare la dichiarazione:
<!ELEMENT prova (EMPTY|paragrafo)>
NO!poiché EMPTY viene interpretato in questo caso come il nome di un sottoelemento di prova, non come parola chiave. Dunque l’elemento così definito deve contenere un elemento EMPTY o un elemento paragrafo e non può essere vuoto. Ovviamente la dichiarazione giusta è:
<!ELEMENT prova (paragrafo?)>
4.2 Dichiarazione degli attributi
Oltre a definirne il contenuto, la DTD consente di associare attributi a ciascun elemento [19]. Gli attributi forniscono informazioni aggiuntive relative ad un elemento o al suo contenuto. A differenza degli elementi, gli attributi possono contenere solo testo, e non markup, al loro interno [1]. Pertanto non esistono "sottoattributi", né in XML, né in SGML (e quindi in HTML).
Nel linguaggio XML, gli attributi vengono dichiarati nella DTD utilizzando la seguente sintassi [19]:
<!ATTLIST ELEMENTO NOME TIPO IMPOSTAZIONE>
dove:
| ELEMENTO è l’elemento al quale viene applicato l’attributo. Si possono trovare attributi con lo stesso nome, ma associati ad elementi diversi. | |
| NOME è il nome dell’attributo; | |
| TIPO è il tipo di attributo; | |
| IMPOSTAZIONE è l’impostazione predefinita dell’attributo. |
Elenchiamo in questa tabella i possibili valori di TIPO:
|
Valore di TIPO |
Valore consentito per l’attributo |
|
CDATA |
Stringa di testo di qualsiasi lunghezza, eventualmente anche vuota. |
|
NMTOKEN |
Stringa composta da lettere, numeri e caratteri ".", "-", ":" e "_" di qualsiasi lunghezza, ma non vuota. |
|
NMTOKENS |
Consente l’utilizzo di più valori di tipo NMTOKEN separati da spazi. |
|
( valore1|valore2|…) |
Deve essere uno dei valori specificati nella lista. |
|
ENTITY |
Riferimento ad un’entità esterna (vedi § 4.4). |
|
ENTITIES |
Riferimenti a diverse entità esterne separati da spazi. |
|
ID |
Identificatore univoco (vedi § 4.2.1). |
|
IDREF |
Riferimento ad un identificatore univoco. |
|
IDREFS |
Riferimenti a diversi identificatori univoci. |
|
NOTATION |
Riferimento ad un’annotazione dichiarata in un altro punto della DTD (vedi § 4.4). |
Il campo IMPOSTAZIONE
può assumere i seguenti valori:|
Valore di IMPOSTAZIONE |
Significato |
|
#REQUIRED |
L’attributo è richiesto. |
|
#IMPLIED |
L’attributo è opzionale. |
|
#FIXED " valore_fissato" |
L’attributo deve avere il valore valore_fissato. Questo può essere specificato nel documento, oppure sottinteso. L’assegnazione di un valore diverso provoca un errore. |
|
" default" |
Se l’attributo non viene specificato, gli viene assegnato il valore default. |
Sono ammesse dichiarazioni di attributi multipli per un singolo elemento [1]. Ad esempio, un elemento PERSONA
potrebbe avere la seguente dichiarazione:<!ATTLIST PERSONA EMAIL CDATA #IMPLIED
TELEFONO CDATA #REQUIRED
FAX CDATA #IMPLIED>
che risulta sicuramente più compatta rispetto a tre dichiarazioni singole.
L’ordine degli attributi non è importante. Infatti, l’elemento:
<PERSONA TELEFONO="071/84315" FAX="071/2810841" EMAIL="mrossi@unian.it">
…</PERSONA>è compatibile con la dichiarazione precedente.
Vediamo un esempio riguardante gli attributi predefiniti:
<!ATTLIST MAGLIETTA TAGLIA (
SMALL|MEDIUM|LARGE) "MEDIUM">In questo caso i valori che può assumere l’attributo TAGLIA sono solo i tre elencati. Il valore predefinito è "MEDIUM". Se nel documento abbiamo:
| <MAGLIETTA TAGLIA="LARGE">…</MAGLIETTA> |
il valore dell’attributo TAGLIA è posto uguale a "LARGE";
| <MAGLIETTA>…</MAGLIETTA> |
<
MAGLIETTA TAGLIA="MEDIUM">…</MAGLIETTA>| Se si tenta di inserire un valore non previsto nell’elenco, si ottiene un errore: |
4.2.1 Riferimenti incrociati
All’interno di un documento XML è possibile effettuare riferimenti incrociati per mezzo degli attributi di tipo ID
e IDREF. Nel documento, l’attributo di tipo ID è in grado di dare un identificatore unico ad un certo elemento, pertanto i valori che esso può assumere sono soggetti alle stesse limitazioni dei nomi di elementi e di attributi, descritte nel § 3.3. Ad esempio, supponiamo di dichiarare il seguente attributo per un elemento SEZIONE:<!ATTLIST SEZIONE argomento ID #IMPLIED>
e supponiamo che vi siano più istanze dell’elemento SEZIONE nel documento, in tal caso sarà possibile riferirsi ad uno di questi utilizzando il suo identificatore univoco. Esso è rappresentato dal valore del suo attributo argomento di tipo ID e deve essere unico all’interno del documento. Naturalmente un elemento non può avere più di un attributo di tipo ID.
L’impostazione #IMPLIED indica che non tutti gli elementi SEZIONE necessitano di un attributo di tipo ID. Se avessimo voluto associare ad ogni elemento SEZIONE un identificatore univoco, avremmo dovuto utilizzare l’impostazione #REQUIRED.
L’assegnazione dell’identificatore all’elemento avviene in questo modo:
<SEZIONE argomento="
Caratteristiche_di_XML">…</SEZIONE>Lo spazio è uno dei caratteri non ammessi per i nomi degli identificatori in XML. Dunque l’assegnazione:
<SEZIONE argomento="Caratteristiche di XML">
…</SEZIONE> NO!è scorretta.
I riferimenti agli identificatori univoci avvengono per mezzo degli attributi di tipo IDREF. Vediamo la dichiarazione di un attributo di questo tipo, assegnato ad un apposito elemento vuoto RIFERIMENTO:
<!ATTLIST RIFERIMENTO A IDREF #REQUIRED>
Il riferimento all’interno del documento è dato da:
<RIFERIMENTO A="
Caratteristiche_di_XML"/>Chiaramente, se il valore dell’attributo A di tipo IDREF non è uguale ad alcun identificatore univoco, si ottiene un errore.
I riferimenti a ciascuno degli identificatori univoci del documento possono essere un numero qualsiasi. È compito del foglio di stile gestire i vari riferimenti, utilizzando presumibilmente dei collegamenti ipertestuali.
4.3 Entità
4.3.1 Entità interne
Le entità sono parti del documento XML che fungono da "contenitori". I loro contenuti possono essere:
| caratteri speciali; | |
| stringhe di testo; | |
| frammenti di documento, composti da testo e markup; | |
| documenti XML situati in file esterni; | |
| file di testo e binari. |
È possibile inserire ciascuno di questi oggetti nel documento tramite un semplice riferimento al nome dell’entità che lo contiene.
Le entità vengono definite nella DTD in questo modo [19]:
<!ENTITY Nome Definizione>
e i riferimenti ad esse all’interno del documento seguono la sintassi:
&Nome;
dove Nome è il nome dell’entità.
Nel caso delle entità interne, Definizione è una parte di documento XML racchiusa tra virgolette o apici, e può contenere [1]:
| testo; | |
| markup; | |
| riferimenti a caratteri (vedi § 3.6); | |
| riferimenti ad altre entità, comprese le entità predefinite (vedi § 3.5). |
Vediamo due esempi:
| <!DOCTYPE EDITORIALE [ |
<par>Perché, allora, pubblicare &IAT;?</par>
<par>La risposta è semplice. &IAT; sarà
</EDITORIALE>
Vengono definite quattro entità: eacute, egrave ed agrave, associate rispettivamente ai caratteri "é", "è" ed "à" come in HTML, e IAT, associata all’elemento TITOLO. Ad ogni riferimento &IAT; viene inserito all’interno del documento l’intero elemento, completo del contenuto:
<TITOLO>
Insieme a tavola</TITOLO>| <!DOCTYPE ESEMPIO [ |
[…]
<ESEMPIO>&uno;</ESEMPIO>
Qualsiasi elemento eventualmente contenuto in un’entità dev’essere completo. In caso contrario il documento non è ben formato. Non è possibile iniziare un elemento in un’entità e finirlo in un’altra:
<!DOCTYPE ESEMPIO [
[…]
<!ENTITY inizio "<TITOLO>Questo esempio ">
NO!<!ENTITY fine "risulta sbagliato.</TITOLO>">
]>
<ESEMPIO>&inizio;&fine;</ESEMPIO>
Lo stesso vale per gli altri tipi di markup: istruzioni di elaborazione, commenti, ecc.
Naturalmente il documento è valido solo se risulta conforme alla sua DTD una volta sostituiti i contenuti delle entità interne ai riferimenti.
4.3.2 Entità esterne
Il linguaggio XML consente di utilizzare file esterni in formato XML o in altri formati per mezzo delle entità esterne. La sintassi della dichiarazione di un’entità esterna è analoga a quella della dichiarazione di una DTD esterna (vedi § 3.4.2). Vediamo un esempio [19]:
<!ENTITY dipartimento SYSTEM "
dipartimentobf.xml">se il file esterno ha un identificatore pubblico, la descrizione dell’entità è composta dalla parola chiave PUBLIC, dall’identificatore pubblico e da un identificatore di sistema da utilizzare nel caso l’identificatore pubblico non sia riconosciuto [6]:
<!ENTITY open-hatch
PUBLIC "-//Textuality//TEXT Standard open-hatch boilerplate//EN"
"
Se l’entità esterna è un file XML, o un file di testo che può far parte del documento XML senza causare errori, essa è detta analizzata e viene riferita con la stessa sintassi delle entità interne (&Nome;). Le entità esterne analizzate consentono di raggruppare vari file in un unico documento XML, come in questo esempio:
<!DOCTYPE TESTO [
<!ELEMENT TESTO (CAPITOLO)+>
<!ELEMENT CAPITOLO (#PCDATA)>
<!ENTITY CAP1 SYSTEM "
Capitolo1.xml"><!ENTITY CAP2 SYSTEM "Capitolo2.xml">
<!ENTITY CAP3 SYSTEM "Capitolo3.xml">
]>
<TESTO>&CAP1; &CAP2; &CAP3;</TESTO>
All’interno del documento vengono sostituiti i tre riferimenti con i contenuti dei file corrispondenti. Mostriamo la visualizzazione di Explorer 5:
<!DOCTYPE TESTO (View Source for full doctype...)>
<
TESTO><
CAPITOLO>Iniziamo con il capitolo 1.</CAPITOLO><
CAPITOLO>Proseguiamo con il capitolo 2.</CAPITOLO><
CAPITOLO>Terminiamo il testo con il capitolo 3.</CAPITOLO></
TESTO>Per usare le entità (escluse quelle predefinite) dev’essere presente la DTD, che serve a definirle. Pertanto, affinché il documento sia valido, le entità esterne analizzate devono:
| essere file privi di una loro DTD, poiché non è ammessa più di una dichiarazione di tipo di documento (DOCTYPE); | |
| rispettare la DTD del documento che le richiama. |
A questo tipo di entità si contrappongono le entità esterne non analizzate. Queste ultime servono ad inserire all’interno di un documento XML immagini, suoni, filmati o altri oggetti multimediali [1]. Si può far riferimento a queste entità per mezzo degli attributi di tipo ENTITY
o ENTITIES, insieme ad una dichiarazione di annotazione, come vedremo nel § 4.4.4.3.3 Entità parametro
Le entità interne ed esterne vengono chiamate entità generali, poiché esse sono definite nella DTD e richiamate all’interno del documento. Oltre a queste esistono anche le entità parametro, che vengono definite e richiamate all’interno della DTD.
La sintassi della dichiarazione di un’entità parametro è la seguente:
<!ENTITY % Nome Definizione>
e il riferimento ad essa avviene in questo modo:
%Nome;
All’interno della dichiarazione il simbolo "%" e il nome dell’entità vanno separati da uno spazio, mentre nel riferimento essi devono essere uniti. Il significato di Definizione è identico a quello delle entità generali.
L’entità parametro non può essere una stringa qualsiasi, ma deve contenere almeno una dichiarazione completa di un elemento o di un attributo, ecc. Vediamo un esempio:
<!DOCTYPE TESTO [
<!ENTITY % parte1 SYSTEM "
dichiarazioni1.ent"><!ENTITY % parte2 SYSTEM "dichiarazioni2.ent">
%parte1; %parte2;
]>
[…]
Le entità parametro esterne, presenti in quest’esempio, permettono di avere parti della DTD in diversi file esterni. Si supera così il limite della DOCTYPE, che consente di dichiarare un unico file come sottoinsieme esterno della DTD (vedi § 3.4.2).
4.4 Annotazioni
L’annotazione è un nome che la DTD assegna ad un certo tipo di file binari. Nella sua dichiarazione c’è un’indicazione per l’elaboratore XML su come operare con tali file [19]. Le dichiarazioni delle varie annotazioni si trovano nella DTD e seguono la sintassi:
<!NOTATION Annotazione Descrizione>
Per incorporare in un documento XML un’entità esterna non analizzata, occorre associarla ad un’annotazione, utilizzando la parola chiave NDATA come in questo esempio:
<!ENTITY sfondo SYSTEM "
palloncini.jpg" NDATA IMMAGINI>IMMAGINI è il nome dell’annotazione, che deve essere a sua volta dichiarata nella DTD. Una possibile dichiarazione di annotazione per l’esempio precedente è:
<!NOTATION IMMAGINI SYSTEM "
Iexplore.exe">la quale indica al software che sta elaborando il documento XML di utilizzare il programma "Iexplore.exe" (Internet Explorer) per gestire i file di tipo IMMAGINI.
Una volta dichiarate, sia le entità esterne che le annotazioni possono comparire nel documento XML come valori di particolari attributi. Ad esempio, possiamo associare ad un elemento ESEMPIO l’entità esterna non analizzata sfondo in questo modo:
<!ATTLIST ESEMPIO FILE ENTITY #REQUIRED>
[…]
<ESEMPIO FILE="
sfondo">…</ESEMPIO>Questo non significa che il documento XML avrà come sfondo il file associato all’entità esterna sfondo. Le annotazioni, infatti, si limitano a fornire informazioni all’elaboratore del documento, che ha il compito di stabilire come l’entità esterna debba essere effettivamente utilizzata, in base:
| alle caratteristiche del sistema di calcolo; | |
| alla disponibilità del programma indicato nell’annotazione; | |
| alle indicazioni del foglio di stile. |
4.5 Creazione della DTD per un documento XML ben formato
Nel § 3.9 abbiamo visto un esempio di conversione di un documento HTML in un documento XML ben formato. Occupiamoci ora di scrivere una DTD compatibile con tale documento, al fine di renderlo valido. Analizzando il codice del documento, si nota che esso rispetta questo schema:
| L’elemento radice è DOCENTI. Esso contiene sei elementi PERSONA. | |
| Ciascun elemento PERSONA contiene, nell’ordine: |
| L’elemento PUBBLICAZIONI contiene uno o più elementi PUBBLICAZIONE, che a loro volta hanno stringhe di testo come contenuto. |
Infine è opportuno definire un’entità per il carattere "è", che viene utilizzato più volte all’interno del documento. Per comodità chiameremo egrave
questa entità, come in HTML.La DTD che esplicita queste regole è la seguente:
<!ELEMENT DOCENTI (PERSONA*)>
<!ELEMENT PERSONA (NOME,GRUPPO,TITOLO?,PUBBLICAZIONI,CURRICULUM)>
<!ELEMENT NOME (#PCDATA)>
<!ELEMENT GRUPPO (#PCDATA)>
<!ELEMENT TITOLO (#PCDATA)>
<!ELEMENT PUBBLICAZIONI (PUBBLICAZIONE+)>
<!ELEMENT PUBBLICAZIONE (#PCDATA)>
<!ELEMENT CURRICULUM (#PCDATA)>
<!ENTITY egrave "è" >
Supponiamo di scrivere questa DTD in un file chiamato "dipartimento.dtd". Per associarla al documento, occorre aggiungere questa riga al prologo:
<!DOCTYPE DOCENTI SYSTEM "
dipartimento.dtd">inoltre nel documento XML occorre sostituire i riferimenti al carattere "è" (è) con i riferimenti all’entità egrave (è). Abbiamo così ottenuto un documento XML valido.
Il documento resta valido se effettuiamo modifiche conformi alla DTD. Ad esempio, possiamo aggiungere un nuovo elemento PERSONA all’interno dell’elemento DOCENTI:
<PERSONA>
<NOME>Antonio Vivaldi</NOME>
<GRUPPO>Sistemi operativi</GRUPPO>
<PUBBLICAZIONI>
</PUBBLICAZIONI>
</PERSONA>
<PERSONA>
<NOME>
Antonio Vivaldi</NOME><GRUPPO>Sistemi operativi</GRUPPO> NO!
<GRUPPO>Reti Neurali</GRUPPO>
[...]
</PERSONA>
il documento non sarebbe più valido. Occorrerebbe la seguente modifica alla DTD, che consente di avere più di un elemento GRUPPO all'interno di PERSONA:
<!ELEMENT PERSONA (NOME,GRUPPO+,TITOLO?,PUBBLICAZIONI,CURRICULUM)>
È chiaro che elencare tutti gli elementi e gli attributi e analizzarne il contenuto, al fine di scrivere una DTD compatibile, può diventare un lavoro lungo e difficile per documenti di grandi dimensioni. Una buona idea è quella di partire da DTD molto "larghe", per poi renderle più ristrette ed aderenti al documento. Per il nostro esempio, è giusta anche la definizione:
<!ELEMENT PERSONA (NOME|GRUPPO|TITOLO|PUBBLICAZIONI|CURRICULUM)*>
secondo cui PERSONA può contenere un numero qualsiasi (eventualmente nessuno) di elementi NOME, GRUPPO, ecc. in un qualsiasi ordine. La semantica di questa definizione è molto povera, però è un buon punto di partenza per evitare errori ed ottenere in seguito una DTD più aderente al documento.
4.6 Spazi dei nomi
Il linguaggio XML consente di assegnare nomi personalizzati ad elementi, attributi, entità, ecc. col vantaggio di una grande flessibiltà, ma con il rischio di generare confusione, utilizzando in diversi documenti di una stessa organizzazione elementi con lo stesso nome e significati diversi.
La soluzione a questo problema è offerta dagli spazi dei nomi XML, che sono "raccolte" di nomi identificate univocamente da un URI (Uniform Resorce Identifier). In XML un URI può essere:
| un URL (Uniform Resource Locator), che è un usuale "indirizzo Internet" ; | |
| un URN (Uniform Resource Name), che è un particolare identificatore associato a ciascuna risorsa in Internet, già discusso nel § 2.6.2. |
La dichiarazione standard per uno spazio dei nomi segue la sintassi [23]:
<ELEMENTO xmlns="URI">
…</ELEMENTO>In questo caso tutti gli elementi e gli attributi di ELEMENTO devono appartenere allo spazio dei nomi identificato da URI. Se ELEMENTO è la radice del documento, tutto il documento apparterrà allo spazio dei nomi specificato. L’attributo xmlns è una parola chiave di XML e può essere usato solo per dichiarare gli spazi dei nomi.
Vediamo un esempio [24]:
<Schema xmlns="urn:schemas-microsoft-com:xml-data">
<ElementType name="
rate" content="textOnly"/>[…]
</Schema>
In questo caso l’elemento Schema e tutti gli elementi ed attributi al suo interno appartengono allo spazio dei nomi urn:schemas-microsoft-com:xml-data, relativo a XML-Data, un’applicazione XML che tratteremo nel prossimo paragrafo.
Se il software che elabora il documento XML è in grado di:
| riconoscere gli spazi dei nomi dichiarati nel documento stesso; | |
| verificare l’effettiva appartenenza di elementi ed attributi agli spazi dei nomi dichiarati; |
allora la DTD diventa superflua, poiché le regole che il documento XML deve seguire sono già definite negli spazi dei nomi.
Gli spazi dei nomi possono essere dichiarati anche per mezzo di una dichiarazione esplicita, la cui sintassi è [23]:
<ELEMENTO xmlns:prefisso="URI">
…</ELEMENTO>In questo modo vengono dichiarati appartenenti allo spazio dei nomi identificato da URI solo gli elementi e gli attributi interni ad ELEMENTO il cui nome inizia con la stringa "prefisso:", che funge da identificatore dello spazio dei nomi. Questo tipo di dichiarazione è particolarmente utile se si desidera far riferimento a più spazi dei nomi nello stesso documento.
Vediamo un esempio in cui viene considerato HTML come spazio dei nomi di XML:
<esempio xmlns:HTML="http://www.w3.org/TR/REC-html40">
<titolo>
HTML all’interno di XML</titolo><logo>
</HTML:A>
</logo>
</esempio>
Solo gli elementi il cui nome è preceduto dalla stringa "HTML:" appartengono allo spazio dei nomi HTML. Utilizzare i tag di HTML in un documento XML può rivelarsi utile per incorporare nel documento elementi di formattazione di HTML, che il foglio di stile potrà lasciare inalterati o affinare ulteriormente. Chiaramente questo è possibile solo se il software supporta anche il linguaggio HTML. Nel nostro esempio HTML è usato per gestire un file grafico ed un brevissimo script, in maniera sicuramente più pratica rispetto all’utilizzo delle entità esterne (si noti che non serve la DTD). È importante che il codice HTML inserito rispetti i vincoli sintattici di XML descritti nel
§ 3.2.2.
4.7 Un’alternativa alla DTD: lo schema XML-Data
4.7.1 Difetti della DTD
La DTD rappresenta la struttura del documento XML e descrive le regole osservate dai dati contenuti in esso [19]. Tuttavia essa presenta alcuni difetti:
Per questo motivo alcune importanti organizzazioni, tra le quali Microsoft, Data Channel e Università di Edimburgo, hanno ideato XML-Data, un’applicazione di XML che ha le stesse funzioni di base della DTD, ma supera i suoi limiti.
4.7.2 Uso dello schema
In XML-Data, la DTD viene sostituita dallo schema, che è a sua volta un documento XML ben formato, con la seguente struttura [24]:
<?xml version="1.0" ?>
<Schema xmlns="urn:schemas-microsoft-com:xml-data">
[Dichiarazioni di elementi e attributi]
</Schema>
Supponiamo che questo schema sia il contenuto del file "schema.xml". Per associare un documento XML ad esso si usa la seguente dichiarazione [23]:
<PROVA xmlns="x-schema:
schema.xml">...</PROVA>In questo modo l’elemento PROVA e tutto il suo contenuto devono rispettare lo schema del file "schema.xml". Non è indispensabile che l’elemento PROVA sia la radice del documento, visto che si utilizza una dichiarazione di appartenza ad uno spazio di nomi, che può trovarsi in qualsiasi parte del documento. Inoltre, utilizzando una dichiarazione esplicita come questa:
<PROVA sch:xmlns="x-schema:
schema2.xml">...</PROVA>sono solo gli elementi:
| figli di PROVA; | |
| il cui nome contiene il prefisso "sch:" |
a dover rispettare lo schema del file "schema2.xml
". È evidente che un documento XML può far riferimento ad un numero qualsiasi di schemi, ciascuno dei quali stabilirà le regole per una certa parte del documento stesso.4.7.3 Dichiarazione degli elementi
Gli elementi vengono dichiarati nello schema con la sintassi:
<ElementType name="
NOME" content="contenuto">…</ElementType>dove:
| NOME è il nome dell’elemento dichiarato; | |
| contenuto può assumere i seguenti valori: |
| "empty" se l’elemento è vuoto, | |
| "textOnly" se l’elemento deve contenere solo testo, | |
| "eltOnly" se l’elemento deve contenere solo sottoelementi, | |
| "mixed" se l’elemento può contenere sia testo che sottoelementi. |
Se contenuto
vale "eltOnly" o "mixed", NOME deve avere degli elementi figli, i quali vengono specificati come contenuto di ElementType utilizzando la sintassi:<element type="nome_figlio"/>
dove nome_figlio è il nome di un elemento dichiarato altrove nello schema, che diventa figlio dell’elemento NOME. Oltre all’attributo type possono comparire i seguenti attributi opzionali:
| minOccurs, che indica il numero minimo di elementi nome_figlio all’interno di NOME; | |
| maxOccurs, che indica il numero massimo di elementi nome_figlio all’interno di NOME. |
Entrambi possono assumere come valore un qualsiasi numero intero, oppure il simbolo "*
", che ha il significato di "numero qualsiasi". Se questi attributi non sono specificati assumono entrambi il valore di default "1".Questa trattazione non esaurisce le possibili dichiarazioni di elementi previste da XML-Data, per le quali si rimanda a [19], ma è sufficiente a realizzare lo schema per il documento XML ben formato del § 3.9:
<?xml version="1.0"?>
<Schema xmlns="urn:schemas-microsoft-com:xml-data">
<ElementType name="
DOCENTI" content="eltOnly"><element type="PERSONA" maxOccurs="*"/>
</ElementType>
<ElementType name="PERSONA" content="eltOnly">
<element type="NOME"/>
<element type="GRUPPO"/>
<element type="TITOLO" minOccurs="0"/>
<element type="PUBBLICAZIONI"/>
<element type="CURRICULUM"/>
</ElementType>
<ElementType name="NOME" content="textOnly"/>
<ElementType name="TITOLO" content="textOnly"/>
<ElementType name="GRUPPO" content="textOnly"/>
<ElementType name="CURRICULUM" content="textOnly"/>
<ElementType name="PUBBLICAZIONI" content="eltOnly">
<element type="PUBBLICAZIONE" maxOccurs="*"/>
</ElementType>
<ElementType name="PUBBLICAZIONE" content="textOnly"/>
</Schema>
Questo schema sostituisce totalmente la DTD del § 4.5, ad eccezione della dichiarazione dell’entità per il carattere "è", in quanto XML-Data non supporta le entità.
Se lo schema viene salvato nel file "schema_dipartimento.xml", l’unica modifica necessaria al documento è la sostituzione del tag di apertura dell’elemento radice <DOCENTI> con:
<DOCENTI xmlns="x-schema:
schema_dipartimento.xml">Pur essendo conforme allo schema, il documento non risulta valido, poiché secondo le specifiche di XML 1.0, un documento è valido solo se rispetta una DTD.
4.7.4 Dichiarazione degli attributi
La dichiarazione degli attributi è analoga a quella degli elementi. Segue la sintassi:
<AttributeType name="
ATTRIBUTO"/>dove ATTRIBUTO è il nome dell’attributo. Diversamente dalla DTD, gli attributi vengono dichiarati indipendentemente dagli elementi. L’assegnazione di un attributo ad un elemento avviene in questo modo:
[Eventuali riferimenti ad altri attributi ed elementi]
</ElementType>
Così abbiamo assegnato ATTRIBUTO all’elemento NOME.
Sia AttributeType che attribute possono avere i seguenti attributi:
| default, che è il valore assegnato all’attributo se questo non compare nel documento; | |
| required, che vale "yes" se l’attributo è obbligatorio. |
Vediamo attraverso alcuni esempi la differenza fra le due possibili collocazioni di questi attributi. Se abbiamo:
<AttributeType name="
EMAIL" required="yes"/>L’attributo EMAIL è obbligatorio per tutti gli elementi del documento che lo prevedono. Viceversa, se required compare in attribute, anziché in AttributeType:
<ElementType name="PERSONA" content="textOnly">
<attribute type="EMAIL" required="yes"/>
</ElementType>
l’attributo EMAIL è obbligatorio solo per l’elemento PERSONA.
Altre caratteristiche degli attributi possono essere definite utilizzando lo spazio dei nomi datatypes, che tratteremo nel capitolo 6, insieme a XML-Data.
4.8 Conclusioni
Per descrivere la struttura di un documento XML è meglio utilizzare la DTD o lo schema di XML-Data? La risposta non è scontata. Gli schemi sono più potenti e flessibili delle DTD, ma non sono ancora uno standard approvato dal W3C, a differenza delle DTD, che sono parte integrante della specifica di XML 1.0. D’altra parte, XML-Data è un’applicazione ideata dalla Microsoft e supportata dal suo browser Explorer 5, quindi la sua diffusione potrebbe spingere il W3C verso una rapida approvazione, come è già accaduto in passato con le estensioni di HTML.
Pertanto, se si prevede di utilizzare software della Microsoft o di altre aziende in grado di supportare XML-Data, è sicuramente preferibile ricorrere agli schemi, mentre in caso contrario è meglio affidarsi alle "tradizionali" DTD, riconosciute da tutti i software in grado di elaborare XML.
5 EXTENSIBLE STYLESHEET LANGUAGE (XSL)
5.1 Associazione di tag HTML agli elementi XML
XSL è un’applicazione XML che può essere usata per manipolare, ordinare e filtrare i dati di un documento XML [25]. I risultati di queste trasformazioni possono essere:
Affinché un documento XML abbia una visualizzazione analoga a quella di HTML, XSL consente di utilizzare tutti i tag di HTML 4.0, seguendo però anche per essi le restrizioni sintattiche di XML esposte nel § 3.2.2.
Vediamo un semplicissimo esempio di foglio di stile XSL [19]:
<?xml version="1.0" ?>
<xsl:template xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<H1><xsl:value-of select="
DOCENTI/PERSONA/NOME"/></H1><H2><xsl:value-of select="DOCENTI/PERSONA/TITOLO"/></H2>
</xsl:template>
in esso compaiono due elementi XSL [36]:
Nel tag di apertura di xsl:template viene dichiarato lo spazio dei nomi di XSL. È indispensabile la dichiarazione esplicita, poiché nei documenti XSL si assume HTML come spazio dei nomi predefinito. Questa scelta permette di inserire i tag di HTML senza alcun prefisso, così come abbiamo fatto con <H1> ed <H2>.
All’interno dell’elemento H1 di HTML viene inserito il valore definito dal pattern di selezione DOCENTI/PERSONA/NOME. Analogamente, in <H2> viene inserito il valore identificato dal pattern DOCENTI/PERSONA/TITOLO. Il significato dei pattern è identico a quello dei percorsi (path) nelle directory di un disco: basta considerare l’albero costituito dal documento XML al posto dell’albero delle directory. Pertanto DOCENTI/PERSONA è il sottoelemento PERSONA dell’elemento DOCENTI.
In sostanza, il foglio di stile effettua le seguenti associazioni fra elementi XML individuati dai propri pattern e tag di HTML:
|
Il contenuto dell’elemento… |
viene assegnato al tag… |
|
|
DOCENTI /PERSONA/NOME |
à |
H1 |
|
DOCENTI /PERSONA/TITOLO |
à |
H2 |
Se nell’albero esistono elementi con lo stesso nome e lo stesso percorso, viene selezionato il primo in ordine di apparizione nel documento. È il caso del nostro esempio illustrato nel § 3.9, in cui l’elemento DOCENTI
ha sei sottoelementi PERSONA. Il pattern DOCENTI/PERSONA seleziona il primo elemento PERSONA, cioè quello relativo al prof. Gianni Brahms, dal quale vengono estratti i valori dei due sottoelementi NOME e TITOLO.Salvando il nostro foglio di stile con il nome di "dipartimento.xsl" e aggiungendo al documento XML del § 3.9, preferibilmente dopo il prologo e prima dell’elemento radice, l’istruzione di elaborazione:
<?xml-stylesheet type="text/xsl" href="
dipartimento.xsl"?>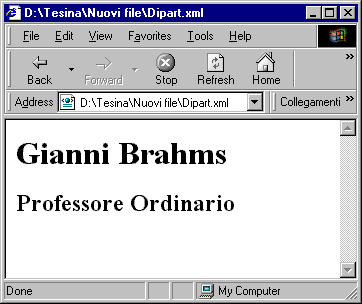
si ottiene il seguente output:
che è lo stesso di questo documento HTML:
<H1>
Gianni Brahms</H1><H2>Professore Ordinario</H2>
Un foglio di stile XSL può essere usato da un numero qualsiasi di documenti, per questo motivo al suo interno non si trovano riferimenti ai file XML che esso deve trasformare.
5.2 Visualizzazione di più elementi con lo stesso nome
Per assegnare un tag HTML a tutti gli elementi XML corrispondenti ad un determinato pattern, occorre utilizzare l’elemento xsl:for-each [19]. Anche esso è dotato di un attributo select, il cui valore deve essere uguale al pattern ripetuto, che nel nostro caso è DOCENTI/PERSONA. A tal proposito applichiamo quest’altro foglio di stile al nostro documento:
<?xml version="1.0" ?>
<xsl:template xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<xsl:for-each select="
DOCENTI/PERSONA"><B><FONT SIZE="5">
</xsl:for-each>
</xsl:template>
L’output che si ottiene è:
Gianni Brahms
(Intelligenza Artificiale)Ermanno Grieg
(Reti Neurali)
Federico Mendelzon
(Visione delle macchine)
Riccardo Strauss
(Basi di Dati)Giuseppe Verdi
(Basi di Dati)Sebastiano Bach
(Ricerca Operativa)
Il valore dell’attributo select del primo elemento xsl:value-of è semplicemente "NOME", anziché l’intero pattern. Questo perché xsl:for-each ha spostato il contesto di applicazione degli elementi XSL dalla radice (DOCENTI) agli elementi PERSONA, ciascuno dei quali ha NOME come figlio. Scrivere "DOCENTI/PERSONA/NOME" al posto di "NOME" avrebbe fatto scomparire tutti i nomi dei docenti, poiché il foglio di stile sarebbe andato a cercare gli elementi DOCENTI/ PERSONA/DOCENTI/PERSONA/NOME, che non esistono. Pertanto, ogni volta che si utilizza un elemento XSL, occorre prestare attenzione al contesto di applicazione.
Si noti, infine, che le parentesi che racchiudono i valori di GRUPPO sono scritte esplicitamente nel foglio di stile.
5.3 Visualizzazione dei valori degli attributi
Se vogliamo visualizzare il valore di un attributo associato ad un elemento, dobbiamo utilizzare l’operatore "@" all’interno del pattern, in questo modo [25]:
<xsl:value-of select="PATTERN/@ATTRIBUTO"/>
dove PATTERN è il percorso associato all’elemento ed ATTRIBUTO è il nome dell’attributo.
Consideriamo, ad esempio, questo breve documento XML:
<?xml version="1.0" ?>
<?xml-stylesheet type="text/xsl" href="
studenti.xsl"?><STUDENTI>
<STUDENTE Matricola="200768">Verdi Fabio</STUDENTE>
<STUDENTE Matricola="937653">Rossi Luca</STUDENTE>
<STUDENTE Matricola="485745">Neri Anna</STUDENTE>
</STUDENTI>
Il foglio di stile per visualizzare sia i nomi che le matricole degli studenti è il seguente:
<?xml version="1.0" ?>
<xsl:template xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<xsl:for-each select="
STUDENTI/STUDENTE"><DIV>Studente: <B><xsl:value-of/></B></DIV>
Matricola: <B><xsl:value-of select="@Matricola"/></B>
<P></P>
</xsl:for-each>
</xsl:template>
da cui si ottiene il seguente output:
Studente: Verdi Fabio
Matricola: 200768
Studente: Rossi Luca
Matricola: 937653
Studente: Neri Anna
Matricola: 485745
Si noti come l’elemento xsl:for-each sposti il contesto dalla radice ai tre elementi STUDENTE, che contengono le informazioni da visualizzare. In questo caso il pattern da inserire negli elementi xsl:value-of è nullo e pertanto:
| nell’elemento xsl:value-of relativo a STUDENTE bisogna eliminare l’attributo select; | |
| nell’elemento xsl:value-of relativo all’attributo Matricola, il pattern è semplicemente "@Matricola", che individua l’attributo Matricola dell’elemento corrispondente al contesto corrente. |
5.4 Fogli di stile contenenti più modelli
Il linguaggio XSL può definire diversi modelli di rappresentazione da applicare indipendentemente alle diverse sezioni del documento XML [19]. In questo caso, ciascun modello è contenuto all’interno di un elemento xsl:template e l’elemento radice del documento XSL diventa xsl:stylesheet, nel quale viene dichiarato lo spazio dei nomi XSL.
La parte del documento alla quale applicare il modello definito all’interno di xsl:template è identificata da un pattern di uguaglianza, che è il valore dell’attributo match [26].
Il modello da applicare a tutto documento deve avere come pattern di uguaglianza il simbolo "/", che rappresenta l’intero documento ed ha come "figlio" l’elemento radice del documento. Ciò significa che, se DOCENTI è la radice del documento, i due pattern "/DOCENTI" e "DOCENTI" sono equivalenti.
Gli altri modelli vengono richiamati attraverso l’elemento xsl:apply-templates, ma vengono applicati solo se viene trovato il loro pattern di uguaglianza a partire dal contesto corrente. L’elemento xsl:apply-templates può trovarsi all’interno di qualsiasi modello.
Questo meccanismo è più difficile da descrivere che da applicare. Vediamo quindi un foglio di stile con più modelli per il documento del § 3.9:
<?xml version="1.0" ?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<xsl:template match="/">
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="
DOCENTI"><xsl:for-each select="PERSONA">
<TABLE BORDER="2"><TR><TD></TD><TD><B>
<xsl:value-of select="NOME"/>
<SMALL><I><xsl:value-of select="TITOLO"/>
</xsl:for-each>
</xsl:template>
<xsl:template match="GRUPPO">
<TR><TD>Gruppo di ricerca:</TD>
<TD><xsl:value-of/></TD></TR>
</xsl:template>
<xsl:template match="CURRICULUM">
<TR><TD>Curriculum vitae:</TD>
<TD><xsl:value-of/></TD></TR>
</xsl:template>
<xsl:template match="PUBBLICAZIONI">
<TR><TD>Pubblicazioni:</TD>
<TD><xsl:for-each select="PUBBLICAZIONE">
<DIV><xsl:value-of/></DIV>
</xsl:for-each></TD></TR>
</xsl:template>
</xsl:stylesheet>
I modelli presenti in questo documento sono cinque:
| il primo è applicato all’intero documento e si limita a richiamare gli altri modelli; | |
| il secondo è applicato all’elemento radice DOCENTI e si occupa di: |
| visualizzare il contenuto degli elementi NOME e TITOLO, | |
| richiamare gli altri modelli; |
| gli altri tre modelli visualizzano il contenuto, rispettivamente, degli elementi GRUPPO, CURRICULUM e PUBBLICAZIONI. |
L’output che si ottiene è il seguente:
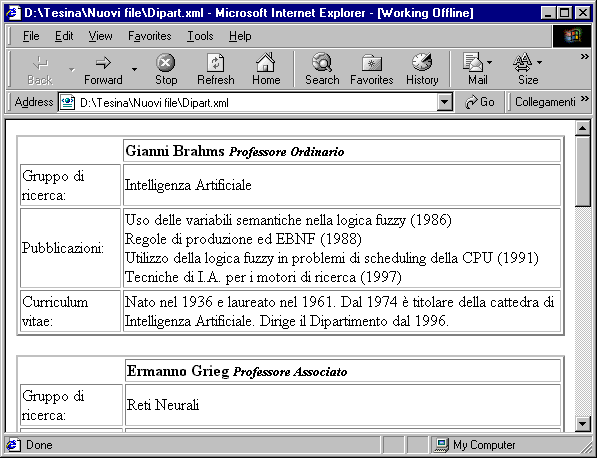
Comunque è possibile scegliere quale modello applicare aggiungendo l’attributo select, già visto per xsl:for-each, all’elemento xsl:apply-templates. Per far comparire il curriculum prima delle pubblicazioni, basta sostituire questi tre elementi:
<xsl:apply-templates select="
GRUPPO"/><xsl:apply-templates select="CURRICULUM"/>
<xsl:apply-templates select="PUBBLICAZIONI"/>
all’unico xsl:apply-templates del modello associato a DOCENTI.
XSL ci consente di visualizzare qualsiasi parte del documento XML, utilizzando un linguaggio di script ed il modello ad oggetti DOM (Document Object Model) [47]. Il DOM è un’interfaccia indipendente da piattaforme e linguaggi che permette a programmi e script di accedere dinamicamente ai documenti HTML ed XML ed aggiornarne il contenuto, la struttura e lo stile. Non entriamo nei dettagli di questo modello, ma ci limitiamo ad introdurre la proprietà nodeName, che restituisce il nome dell’elemento o dell’attributo corrispondente al contesto corrente. È chiamata così perché il DOM considera elementi, attributi, entità, commenti, ecc. come nodi dell’albero associato al documento XML.
Per supportare gli script, la Microsoft ha introdotto due elementi aggiuntivi ad XSL [36]. Essi sono [19]:
| xsl:script: contiene gli script che verranno richiamati all’interno del foglio di stile. | |
| xsl:eval: valuta lo script al suo interno. |
Fatte queste premesse, consideriamo il seguente foglio di stile, da abbinare al documento del § 3.9:
<?xml version="1.0" ?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<xsl:template match="/">
<TABLE BORDER="3"><xsl:apply-templates/></TABLE>
</xsl:template>
<xsl:template match="*">
<TR><TH><xsl:eval>nodeName;</xsl:eval></TH></TR>
<xsl:for-each select="
PERSONA"><TR><TD><xsl:value-of select="*"/>
<SMALL><I>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
Il titolo della tabella, contenuto all’interno del tag <TH> di HTML, è posto uguale al nome dell’elemento radice, identificato con il carattere jolly "*", anziché con il suo nome. Torneremo sul carattere jolly e sugli operatori consentiti all’interno dei pattern nel § 6.3. L’output che si ottiene è:
N.B. In Explorer 5, lo stesso risultato di:
<xsl:eval>nodeName;</xsl:eval>
si può ottenere con l’elemento [19]:
<xsl:node-name/>
Tuttavia, anche questo elemento è un’aggiunta della Microsoft e non compare nella bozza di lavoro del W3C [26]. Stranamente, tale elemento non viene citato nemmeno nella guida di XSL della Microsoft, sebbene utilizzato in alcuni esempi all’interno di questa [36].
Pur avendo esaminato solo una parte degli elementi di XSL, abbiamo già gli strumenti necessari per introdurre i dati di un documento XML in una "pagina Web". Possiamo così concludere il lavoro sul documento XML introdotto nel § 3.9, fornendo ad esso un foglio di stile XSL che lo visualizzi in maniera simile al documento HTML dal quale lo avevamo convertito.
È importante reinserire nel foglio di stile tutti quelle parti del documento HTML che avevamo soppresso nella conversione all’XML. In questo modo viene realizzata una delle caratteristiche più importanti di XML, cioè la separazione fra:
| i dati del documento, descritti formalmente dalla DTD e dalla struttura ad albero imposta da XML; | |
| la presentazione del documento, costituita da un foglio di stile XSL formato da elementi che stabiliscono le relazioni con il documento XML e tag di HTML. Nel foglio di stile devono comparire anche quelle parti di testo che rendono più leggibili i dati, ma che non fanno parte di essi. |
Ecco un foglio di stile per il "nostro" documento XML che si avvicina al documento HTML dal quale eravamo partiti:
<?xml version="1.0" ?>
<HTML xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<HEAD><TITLE>
Università di QualchePosto - Docenti del dipartimento di Informatica
</TITLE></HEAD>
<BODY>
<FONT COLOR="#0000ff">
<H1 ALIGN="CENTER">Università degli studi di QualchePosto</H1>
<H2 ALIGN="CENTER">Dipartimento di Informatica</H2>
</FONT>
<I><FONT COLOR="#ff00ff"><H3 ALIGN="CENTER">Elenco dei docenti</H3></FONT></I>
<DIV STYLE="font-family:Times, helvetica, sans-serif; background-color:#EEEEEE">
<xsl:for-each select="DOCENTI/PERSONA">
<DIV STYLE="background-color:red; color:white; padding:4px">
<B COLOR="WHITE"><xsl:value-of select="NOME"/></B>:
<xsl:value-of select="TITOLO"/>
</DIV>
<DIV STYLE="margin-left:15px;">
Gruppo di ricerca: <I><xsl:value-of select="GRUPPO"/></I>
</DIV>
<P STYLE="margin-left:15px;">
Curriculum vitae: <xsl:value-of select="CURRICULUM"/>
</P>
<P STYLE="margin-left:15px;">Elenco pubblicazioni:<UL>
<xsl:for-each select="PUBBLICAZIONI/PUBBLICAZIONE">
<LI><xsl:value-of/></LI>
</xsl:for-each>
</UL></P>
</xsl:for-each>
</DIV>
</BODY>
</HTML>
La visualizzazione che si ottiene è la seguente:
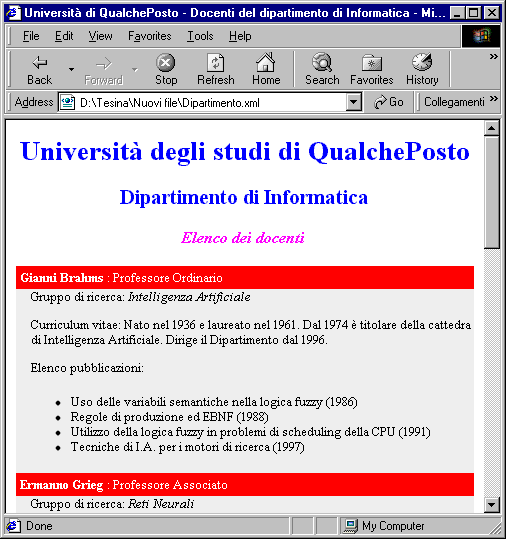
Per migliorare la presentazione della pagina, abbiamo aggiunto ad alcuni tag di HTML l’attributo STYLE, che ci consente di assegnare ai singoli tag gli attributi di formattazione di CSS (vedi
§ 2.1.2). Questa tecnica è detta CSS in linea ed è uno dei metodi forniti da HTML 4.0 per implementare i fogli di stile CSS [27]. È possibile utilizzarla all’interno di un documento XSL, poiché in esso si può inserire tutto ciò che può trovarsi in un documento HTML, come fogli di stile CSS, applet Java, script vari, ecc.
In generale, la stesura di un foglio di stile XSL si può riassumere in questi punti:
Si noti che gli elementi di XSL servono solo per il punto 1). Per le altre operazioni è sufficiente conoscere HTML ed eventualmente anche Javascript o DHTML, nel caso si voglia realizzare una pagina Web sofisticata.
Quanto abbiamo visto finora è una piccola parte delle potenzialità di XSL. Esso è capace anche di:
| trasformare un documento XML in un altro documento XML, come vedremo nel § 5.8; | |
| effettuare filtraggi, ordinamenti ed interrogazioni sui dati di un documento XML. Di questo ci occuperemo ampiamente nel prossimo capitolo. |
Internet Explorer 5 consente l’elaborazione dei documenti XML per mezzo delle isole di dati XML [19]. Grazie alle isole di dati, è possibile introdurre interi documenti XML direttamente all’interno di una pagina HTML. L’isola di dati XML è contenuta all’interno dell’elemento <XML>, e può essere identificata tramite il valore dell’attributo ID:
<XML ID="Nome">Documento_XML</XML>
Vediamo un esempio:
<HTML>
<HEAD><TITLE>
XML all'interno di HTML</TITLE></HEAD><BODY>
<XML ID="Studenti">
<?xml version="1.0" ?>
<STUDENTI>
<STUDENTE Matricola="200768">Verdi Fabio</STUDENTE>
<STUDENTE Matricola="937653">Rossi Luca</STUDENTE>
<STUDENTE Matricola="485745">Neri Anna</STUDENTE>
</STUDENTI>
</XML>
</BODY>
</HTML>
In alternativa, l’isola di dati può contenere un documento XML esterno, il cui indirizzo è specificato dall’attributo SRC:
<HTML>
<HEAD>
<TITLE>
XML all'interno di HTML</TITLE></HEAD>
<BODY>
<XML ID="Dipartimento" SRC="dipartimentobf.xml"></XML>
</BODY>
</HTML>
Caricando con il browser i due precedenti documenti HTML, si ottengono due pagine vuote, poiché non è specificato quali dati dell’isola debbano essere mostrati. Explorer 5 consente di visualizzare ed elaborare il contenuto di un’isola XML utilizzando il modello ad oggetti DOM insieme ad un linguaggio di script [25]. Mostriamo un documento HTML che [26]:
| carica un documento XML nell’isola di dati source; | |
| carica un foglio di stile XSL nell’isola di dati style; | |
| visualizza il documento XML attraverso il foglio di stile XSL: |
<HTML>
<XML id=
source src="dipartimento.xml"></XML><XML id=style src="dipartimento.xsl"></XML>
<SCRIPT event=onload for=window>
xslTarget.innerHTML = source.transformNode(style.XMLDocument);
</SCRIPT>
<BODY><SPAN id=xslTarget></SPAN></BODY>
</HTML>
Se "dipartimento.xml" è il documento XML del § 3.9 e "dipartimento.xsl" è il foglio di stile del paragrafo precedente, il documento HTML ci dà lo stesso output prodotto dal documento XML visualizzato con il foglio di stile. L’unica eccezione è il titolo della pagina HTML, che resta indefinito e non diventa quello specificato nel documento XSL. Per risolvere questo piccolo inconveniente, inseriamo la seguente modifica:
<HTML>
<XML id=
source src="dipartimento.xml"></XML><XML id=style src="dipartimento.xsl"></XML>
<SCRIPT event=onload for=window>
document.write(source.transformNode(style.XMLDocument));
</SCRIPT>
</HTML>
Tale sistema presenta anche un altro vantaggio: se chiediamo al browser di mostrarci il codice sorgente del documento, non otteniamo le righe scritte qui sopra, bensì questo listato:
<HTML xmlns:xsl="http://www.w3.org/TR/WD-xsl">
[…]
<DIV STYLE="font-family:Times, helvetica, sans-serif; background-color:#EEEEEE">
<DIV STYLE="background-color:red; color:white; padding:4px">
<B COLOR="WHITE">
Gianni Brahms</B>:Professore Ordinario</DIV>
<DIV STYLE="margin-left:15px;">
Gruppo di ricerca: <I>Intelligenza Artificiale</I></DIV>
<P STYLE="margin-left:15px;">
Curriculum vitae: Nato nel 1936 e laureato nel 1961. Dal 1974 è titolare della cattedra di Intelligenza Artificiale. Dirige il Dipartimento dal 1996.</P>
[…]
che è il documento HTML ottenuto dall’applicazione del foglio di stile XSL al documento XML. Tale risultato è particolarmente utile per visualizzare ed archiviare i risultati delle trasformazioni di documenti XML in altri documenti XML che XSL è in grado di effettuare. Quest’aspetto sarà trattato nel prossimo paragrafo.
5.8 Trasformazione di documenti XML attraverso XSL
5.8.1 Estrazione di un sottoalbero da un documento XML
Il linguaggio XSL mette a disposizione un insieme di elementi in grado di operare trasformazioni sui documenti XML. Tra questi il più semplice è xsl:copy, che include una copia del nodo specificato dall’attributo select nel documento destinazione [19].
Il foglio di stile che presentiamo estrae il terzo elemento PERSONA con tutto il suo contenuto dal documento del § 3.9 [25]:
<?xml version="1.0" ?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<xsl:template match="/">
<xsl:apply-templates select="
DOCENTI/PERSONA[2]"><xsl:template>
<xsl:copy>
<xsl:apply-templates select="@* | * | text()"/>
</xsl:copy>
</xsl:template>
</xsl:apply-templates>
</xsl:template>
</xsl:stylesheet>
Questo foglio di stile funziona grazie all’applicazione ricorsiva dei modelli XSL. In particolare:
NOME
[n-1]Il documento XML che si ottiene è:
<PERSONA>
<NOME>
Federico Mendelzon
</NOME>
<GRUPPO>
Visione delle macchine
</GRUPPO>
<PUBBLICAZIONI>
<PUBBLICAZIONE>
Progetto di un software in grado di riconoscere i tombini (1999)
</PUBBLICAZIONE>
</PUBBLICAZIONI>
<CURRICULUM>
Nato nel 1971 e laureato nel 1998. Collabora con il prof. Brahms nel corso di Intelligenza artificiale.
</CURRICULUM>
</PERSONA>
5.8.2 Aggiunta di nuovi nodi ad un documento XML
Oltre ad estrarre parti di un documento XML, XSL è in grado di aggiungere ad esso nuovi componenti, per mezzo degli elementi [26]:
| xsl:element: genera un elemento con il nome specificato dall’attributo name; | |
| xsl:attribute: genera un attributo con il nome specificato dall’attributo name; | |
| xsl:pi: genera un’istruzione di elaborazione con il nome specificato dall’attributo name; | |
| xsl:comment: genera un commento. |
Vediamo, a tal proposito, il seguente foglio di stile:
<?xml version="1.0" ?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<xsl:template match="/">
<xsl:pi name="
xml"><xsl attribute name="version">1.0</xsl:attribute>
</xsl:pi>
<xsl:element name="SCHEDA">
<xsl:attribute name="Codice">D375K</xsl:attribute>
<xsl:comment>
Questa e' la terza scheda dell'archivio DOCENTI
</xsl:comment>
<xsl:apply-templates select="DOCENTI/PERSONA[2]">
<xsl:template>
<xsl:copy>
<xsl:apply-templates select="@* | * | text()"/>
</xsl:copy>
</xsl:template>
</xsl:apply-templates>
</xsl:element>
</xsl:template>
</xsl:stylesheet>
Il foglio di stile produce il documento XML dell’esempio precedente, con le seguenti aggiunte:
Il documento XML che risulta da queste trasformazioni è, infatti:
<?xml version="1.0"?>
<SCHEDA Codice="
D375K"><!--Questa e' la terza scheda dell'archivio DOCENTI-->
<PERSONA>
<NOME>
Federico Mendelzon
</NOME>
[…]
</PERSONA>
</SCHEDA>
5.9 Conclusioni
Il linguaggio XSL consente di visualizzare i documenti XML non solo tramite i tag di HTML, ma anche utilizzando gli oggetti di formattazione (Formatting Object). Questi sono descritti in dettaglio da una enorme bozza di lavoro del W3C [28]: 249 pagine, nelle quali non compare nemmeno un esempio. Viceversa, gli elementi di XSL visti finora, e che continueremo ad utilizzare nel prossimo capitolo, sono definiti nella specifica XSL Transformations [26].
Vediamo un semplice esempio nel quale viene richiamato un oggetto di formattazione, perceduto dal prefisso "fo" [29]:
<xsl:template match="
synopsis//emphasis"></fo:inline-sequence>
</xsl:template>
Sull’utilità degli oggetti di formattazione si è aperto un acceso dibattito nell’ambiente degli sviluppatori XML. In particolare, Michael Leventhal della Citec ha pubblicato una vera e propria "dichiarazione di guerra" ad XSL [30].
Il mio parere personale è che le trasformazioni permesse da XSL siano molto utili e che la possibilità di produrre un output HTML a partire da un documento XML sia sufficiente per la maggior parte delle applicazioni Web. Queste funzionalità sono già offerte da diversi software, primo fra tutti Explorer 5. Viceversa, gli oggetti di formattazione sono al momento supportati solo da un paio di programmi, che non permettono la visualizzazione diretta del documento formattato, ma lo convertono in un file che deve essere successivamente letto con Acrobat [31]. Risulta evidente, pertanto, che gli oggetti di formattazione di XSL costituiscono un linguaggio molto complesso, che ha scarse possibilità di affermarsi nel Web, almeno a breve termine.
6 GESTIONE DI UNA SEMPLICE BASE DI DATI CON XML
6.1 Spazio dei nomi datatypes
In questo capitolo tratteremo l’utilizzo del linguaggio XML come fonte di dati. In particolare ci occuperemo della rappresentazione in XML di una semplice base di dati, definendone lo schema e i tipi di dati contenuti in essa. Successivamente vedremo come XSL consenta di effettuare interrogazioni, ordinamenti e filtraggi anche piuttosto complessi sui dati contenuti nel documento XML. Chiuderemo con alcune considerazioni sullo stato attuale dello sviluppo di XSL.
Iniziamo dalla "tipizzazione" dei dati. Lo spazio dei nomi:
urn:schemas-microsoft-com:datatypes
permette di specificare il formato dei dati contenuti negli elementi e negli attributi [23]. Esso può essere utilizzato insieme agli schemi di XML-Data in questo modo:
<Schema name="mio_schema" xmlns="urn:schemas-microsoft-com:xml-data" xmlns:dt="urn:schemas-microsoft-com:datatypes"> […] </Schema>
All’interno dello schema, ci sono due possibilità per specificare il tipo di dati di un elemento o di un attributo:
<ElementType name="
pagine" dt:type="int"/>che definisce l’elemento pagine, il quale deve avere un numero intero (int) come contenuto.
L’altro metodo per specificare i tipi di dati consiste nel dichiarare lo spazio dei nomi datatypes direttamente nel documento XML [24]. Solitamente, per comodità, viene associato ad esso il prefisso "dt
":<elemento xmlns:dt="urn:schemas-microsoft-com:datatypes">
[…]
</elemento>
In questo caso, però, è possibile specificare solo i dati contenuti negli elementi, e non i valori degli attributi. La dichiarazione dello spazio dei nomi, che abbiamo appena visto, deve essere nell’elemento radice o, comunque, in un elemento che abbia come figli tutti gli elementi di cui vogliamo specificare il contenuto. Questa dichiarazione ci consente di utilizzare lo spazio dei nomi datatypes anche in documenti ben formati, privi di schema o DTD.
La sintassi per specificare il contenuto dell’elemento NOME è:
<NOME dt:dt="tipo">Contenuto</NOME>
Contenuto
deve essere un dato del tipo specificato da tipo. Chiaramente NOME non può avere sottoelementi.I tipi di dati disponibili sono i seguenti [32]:
|
tipo |
Descrizione |
Esempio |
|
string |
Stringa |
Questa e’ una stringa. |
|
bin.base64 |
Blocco binario codificato in base 64 |
O |
|
bin.hex |
Cifra esadecimale |
E |
|
boolean |
0 (equivale a "falso") o 1 (equivale a "vero") |
1 |
|
char |
Carattere (stringa di un solo carattere) |
X |
|
date |
Data in formato ISO 8601 |
1999-06-24 |
|
dateTime |
Data e ora (opzionale) in formato ISO 8601 |
1999-06-24 T10:26:15.44 |
|
dateTime.tz |
Data e ora (opzionale) in formato ISO 8601, con indicazione opzionale del fuso orario |
1999-06-24 T10:26:15+02:00 |
|
fixed.14.4 |
Numero decimale, con un massimo di 14 cifre intere e 4 decimali |
12.0044 |
|
float |
Numero decimale in virgola mobile |
1.7976931348623157E+308 |
|
int |
Numero intero |
58502 |
|
number |
Numero (identico a "float") |
3.14 |
|
time |
Ora in formato ISO 8601 |
06:15:31 |
|
time.tz |
Ora in formato ISO 8601, con indicazione opzionale del fuso orario |
10:39:42.7571+02:00 |
|
i1 |
Numero intero rappresentato in un byte |
127 |
|
i2 |
Numero intero rappresentato in 2 byte |
-32768 |
|
i4 |
Numero intero rappresentato in 4 byte |
148343 |
|
r4 |
Numero reale rappresentato in 4 byte |
3.141592 |
|
r8 |
Numero reale rappresentato in 8 byte (identico a "float" e "number") |
2.2250738585072014E-308 |
|
ui1 |
Numero naturale rappresentato in un byte |
255 |
|
ui2 |
Numero naturale rappresentato in 2 byte |
65535 |
|
ui4 |
Numero naturale rappresentato in 4 byte |
3000000000 |
|
uri |
Universal Resource Identifier (URI) |
urn:schemas-microsoft-com:datatypes |
|
uuid |
Sequenza di cifre esadecimali, che possono essere separate da trattini |
333C7BC4-460F-11D0-BC04-0080C7055A83 |
Vediamo un esempio [1]:
<vestito xmlns:dt="urn:schemas-microsoft-com:datatypes">
[…]
<taglia dt:dt="ui1">42</taglia>
</vestito>
La taglia di un vestito si può rappresentare con un numero naturale di un solo byte. Abbiamo usato, pertanto, il tipo di dati corrispondente, che è "ui1".
Lo spazio dei nomi datatypes viene usato per definire i tipi di attributi all’interno degli schemi di XML-Data. I valori degli attributi possono appartenere, oltre che ai tipi elencati nel paragrafo precedente, anche ai tipi di dati "primitivi" definiti da XML [19]. Rivediamo questi tipi di dati e come possono essere dichiarati all’interno dell’elemento AttributeType:
|
Tipo primitivo |
Dichiarazione all’interno di AttributeType |
|
CDATA |
dt:type="string" |
|
NMTOKEN |
dt:type="nmtoken" |
|
NMTOKENS |
dt:type="nmtokens" |
|
( valore1|valore2|…) |
dt:type="enumeration" dt:values=" valore1 valore2 …" |
|
ENTITY |
dt:type="entity" |
|
ENTITIES |
dt:type="entities" |
|
ID |
dt:type="id" |
|
IDREF |
dt:type="idref" |
|
IDREFS |
dt:type="idrefs" |
|
NOTATION |
dt:type="notation" |
Questi tipi di dati sono stati illustrati nei §§ 4.2 e 4.4. Vediamo, ad esempio, come si definisce un identificatore univoco argomento per l’elemento SEZIONE in XML-Data:
<Schema xmlns="urn:schemas-microsoft-com:xml-data"
xmlns:dt="urn:schemas-microsoft-com:datatypes">
<AttributeType name="
argomento" dt:type="id" required="no"/><ElementType name="SEZIONE" content="mixed">
<attribute type="argomento"/>
[…]
</ElementType>
[…]
</Schema>
6.2 Rappresentazione in XML di una semplice base di dati
6.2.1 Definizione dello schema
Consideriamo una piccola base di dati contenente due tabelle [3]:
IMPIEGATO (
Matricola, Nome, Cognome, Dipart, Ufficio, Stipendio)DIPARTIMENTO (
Nome, Indirizzo, Città)Ogni tabella è rappresentata del suo nome, seguito dall’elenco dei nomi delle sue colonne racchiuso fra parentesi. Sono sottolineate le chiavi primarie delle due tabelle. La chiave primaria è un insieme di colonne, i cui dati sono in grado di identificare univocamente ciascuna riga della tabella. La tabella IMPIEGATO ha come chiave primaria la colonna Matricola, mentre la tabella DIPARTIMENTO ha come chiave primaria la colonna Nome.
I database consentono la definizione di chiavi primarie multiparte, costituite da più di una colonna [5]. Questa possibilità è prevista nella bozza di lavoro di XML-Data presentata al W3C, ma, al momento, non è ancora implementata in Explorer 5 [33]. Per questo motivo ci limitiamo ad utilizzare colonne singole come chiavi, realizzandole per mezzo degli identificatori univoci di XML (vedi
§ 4.2.1).
Nella terminologia delle basi di dati, le righe della tabella sono chiamate tuple, mentre i nomi delle colonne sono detti attributi. Per evitare confusione con gli attributi di XML, continueremo a usare il termine generico "nomi delle colonne". Fatte queste premesse, vediamo lo schema XML-Data che descrive la nostra base di dati:
<?xml version="1.0"?>
<Schema name="
DataBase"xmlns="urn:schemas-microsoft-com:xml-data"
xmlns:dt="urn:schemas-microsoft-com:datatypes">
<ElementType name="DATABASE" content="eltOnly">
<element type="IMPIEGATI"/>
<element type="DIPARTIMENTI"/>
</ElementType>
<ElementType name="IMPIEGATI" content="eltOnly">
<element type="IMPIEGATO" maxOccurs="*"/>
</ElementType>
<AttributeType name="Matricola" dt:type="id" required="yes"/>
<AttributeType name="Dipart" dt:type="idref" required="yes"/>
<ElementType name="IMPIEGATO" content="eltOnly">
<element type="Nome"/>
<attribute type="Matricola"/>
<element type="Cognome"/>
<attribute type="Dipart"/>
<element type="Ufficio"/>
<element type="Stipendio"/>
</ElementType>
<ElementType name="Nome" content="textOnly"/>
<ElementType name="Cognome" content="textOnly"/>
<ElementType name="Ufficio" dt:type="ui1"/>
<ElementType name="Stipendio" dt:type="r4"/>
<ElementType name="DIPARTIMENTI" content="eltOnly">
<element type="DIPARTIMENTO" maxOccurs="*"/>
</ElementType>
<AttributeType name="Nome" dt:type="id" required="yes"/>
<ElementType name="DIPARTIMENTO" content="eltOnly">
<attribute type="Nome"/>
<element type="Indirizzo"/>
<element type="Citta"/>
</ElementType>
<ElementType name="Indirizzo" content="textOnly"/>
<ElementType name="Citta" content="textOnly"/>
</Schema>
Alcuni commenti:
| la tabella IMPIEGATI è rappresentata dall’omonimo elemento e ciascuna sua tupla è contenuta in un elemento IMPIEGATO. | |
| La chiave primaria Matricola di IMPIEGATI è realizzata con un identificatore univoco (attributo di tipo "id"). | |
| La colonna Dipart è realizzata con un attributo di tipo "idref", poiché contiene riferimenti alle tuple della tabella DIPARTIMENTI, tramite le loro chiavi primarie. | |
| L’elemento Ufficio deve contenere un numero intero compreso tra 0 e 255 (dato di tipo "ui1"). | |
| L’elemento Stipendio deve contenere un numero reale rappresentato in 4 byte (dato di tipo "r4"). | |
| Gli elementi Nome e Cognome contengono stringhe di testo. | |
| La tabella DIPARTIMENTI è rappresentata dall’omonimo elemento e ciascuna sua tupla è contenuta in un elemento DIPARTIMENTO. | |
| La chiave primaria Nome di DIPARTIMENTI è un identificatore univoco. | |
| Gli elementi Indirizzo e Citta contengono stringhe di testo. Ricordiamo che i nomi degli elementi XML non possono contenere lettere accentate, né apostrofi, dunque non possono esistere in XML tag <Città> o <Citta’>. |
La bozza di lavoro di XML-Data prevede altre caratteristiche per gli schemi, non ancora implementate in Explorer 5, tra cui la possibilità di definire la lunghezza massima di ciascuna stringa e di limitare entro un particolare intervallo i valori numerici. Non sappiamo se lo sviluppo di XML-Data sarà portato a termine, poiché il W3C sta lavorando su un altro linguaggio per la definizione degli schemi, chiamato XML-Schema [34].
6.2.2 Definizione dello schema tramite una DTD
Lo schema presentato nel paragrafo precedente equivale alla seguente DTD:
<!ELEMENT DATABASE (IMPIEGATI,DIPARTIMENTI)>
<!ELEMENT IMPIEGATI (IMPIEGATO+)>
<!ELEMENT IMPIEGATO (Nome,Cognome,Ufficio,Stipendio)>
<!ATTLIST IMPIEGATO Matricola ID #REQUIRED
Dipart IDREF #REQUIRED>
<!ELEMENT Nome (#PCDATA)>
<!ELEMENT Cognome (#PCDATA)>
<!ELEMENT Ufficio (#PCDATA)>
<!ATTLIST Ufficio xmlns:dt CDATA #FIXED "urn:schemas-microsoft-com:datatypes"
dt:dt CDATA #FIXED "ui1">
<!ELEMENT Stipendio (#PCDATA)>
<!ATTLIST Stipendio xmlns:dt CDATA #FIXED "urn:schemas-microsoft-com:datatypes"
dt:dt CDATA #FIXED "r4">
<!ELEMENT DIPARTIMENTI (DIPARTIMENTO+)>
<!ELEMENT DIPARTIMENTO (Indirizzo,Citta)>
<!ATTLIST DIPARTIMENTO Nome ID #REQUIRED>
<!ELEMENT Indirizzo (#PCDATA)>
<!ELEMENT Citta (#PCDATA)>
Lo spazio dei nomi datatypes è stato realizzato per essere richiamato dagli schemi di XML-Data, oppure da documenti XML privi di schema. Dunque il suo utilizzo con le DTD risulta difficoltoso. In particolare, lo spazio dei nomi deve essere dichiarato per ogni elemento di cui vogliamo specificare il tipo di contenuto. Nel nostro caso gli elementi sono solo due: Ufficio e Stipendio, e le rispettive dichiarazioni sono evidenziate in giallo nel precedente listato; in generale, però, questo sistema risulta scomodo. L’alternativa migliore consiste nel dichiarare lo spazio dei nomi e i tipi degli elementi direttamente nel documento, come abbiamo visto nel § 6.1 per i documenti privi di schema, eliminando così dalla DTD le righe evidenziate in giallo.
La scarsa compatibilità con gli spazi dei nomi è uno dei difetti principali delle DTD, e deriva dal fatto che le DTD sono nate con SGML, mentre gli spazi dei nomi sono una tecnologia molto più recente [35]. È evidente, pertanto, la necessità di implementare un linguaggio per la definizione degli schemi pienamente compatibile con gli spazi dei nomi e che offra le potenzialità dei moderni database, altrimenti sarà impossibile realizzare delle vere basi di dati tramite XML. Vedremo se XML-Data o XML-Schema riusciranno in questa difficile impresa.
6.2.3 Documento XML contenente i dati
Supponiamo che le tabelle definite precedentemente siano riempite da questi dati [3]:
IMPIEGATI
|
Matricola |
Nome |
Cognome |
Dipart |
Ufficio |
Stipendio |
|
RSSMRA BNCCRL VRDGSP NREFRN RSSCRL LNZLRN BRRPLA FRNMRC |
Mario Carlo Giuseppe Franco Carlo Lorenzo Paola Marco |
Rossi Bianchi Verdi Neri Rossi Lanzi Borroni Franco |
Amministrazione Produzione Amministrazione Distribuzione Direzione Direzione Amministrazione Produzione |
10 20 20 16 14 7 75 20 |
45 36 40 45 80 73 40 46 |
DIPARTIMENTI
|
Nome |
Indirizzo |
Città |
|
Amministrazione Produzione Distribuzione Direzione Ricerca |
Via Tito Livio, 27 P.le Lavater, 3 Via Segre, 9 Via Tito Livio, 27 Via Morone, 6 |
Milano Torino Roma Milano Milano |
Notiamo che:
| la matricola è composta dalle prime sei lettere del codice fiscale. Non sarebbe stato possibile utilizzare un numero, visto che gli identificatori univoci di XML devono obbligatoriamente iniziare con una lettera. | |
| Nella colonna Stipendio compare lo stipendio annuo in milioni di lire. |
Vediamo il documento XML che contiene questi dati, strutturati secondo lo schema del § 6.2.1 o, equivalentemente, secondo la DTD del paragrafo precedente:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="
DB.xsl"?><DATABASE xmlns="x-schema:DBschema.xml">
<IMPIEGATI>
<IMPIEGATO Matricola="RSSMRA" Dipart="Amministrazione">
<Nome>Mario</Nome>
<Cognome>Rossi</Cognome>
<Ufficio>10</Ufficio>
<Stipendio>45</Stipendio>
</IMPIEGATO>
<IMPIEGATO Matricola="BNCCRL" Dipart="Produzione">
<Nome>Carlo</Nome>
<Cognome>Bianchi</Cognome>
<Ufficio>20</Ufficio>
<Stipendio>36</Stipendio>
</IMPIEGATO>
<IMPIEGATO Matricola="VRDGSP" Dipart="Amministrazione">
<Nome>Giuseppe</Nome>
<Cognome>Verdi</Cognome>
<Ufficio>20</Ufficio>
<Stipendio>40</Stipendio>
</IMPIEGATO>
<IMPIEGATO Matricola="NREFRN" Dipart="Distribuzione">
<Nome>Franco</Nome>
<Cognome>Neri</Cognome>
<Ufficio>16</Ufficio>
<Stipendio>45</Stipendio>
</IMPIEGATO>
<IMPIEGATO Matricola="RSSCRL" Dipart="Direzione">
<Nome>Carlo</Nome>
<Cognome>Rossi</Cognome>
<Ufficio>14</Ufficio>
<Stipendio>80</Stipendio>
</IMPIEGATO>
<IMPIEGATO Matricola="LNZLRN" Dipart="Direzione">
<Nome>Lorenzo</Nome>
<Cognome>Lanzi</Cognome>
<Ufficio>7</Ufficio>
<Stipendio>73</Stipendio>
</IMPIEGATO>
<IMPIEGATO Matricola="BRRPLA" Dipart="Amministrazione">
<Nome>Paola</Nome>
<Cognome>Borroni</Cognome>
<Ufficio>75</Ufficio>
<Stipendio>40</Stipendio>
</IMPIEGATO>
<IMPIEGATO Matricola="FRNMRC" Dipart="Produzione">
<Nome>Marco</Nome>
<Cognome>Franco</Cognome>
<Ufficio>20</Ufficio>
<Stipendio>46</Stipendio>
</IMPIEGATO>
</IMPIEGATI>
<DIPARTIMENTI>
<DIPARTIMENTO Nome="Amministrazione">
<Indirizzo>Via Tito Livio, 27</Indirizzo>
<Citta>Milano</Citta>
</DIPARTIMENTO>
<DIPARTIMENTO Nome="Produzione">
<Indirizzo>P.le Lavater, 3</Indirizzo>
<Citta>Torino</Citta>
</DIPARTIMENTO>
<DIPARTIMENTO Nome="Distribuzione">
<Indirizzo>Via Segre, 9</Indirizzo>
<Citta>Roma</Citta>
</DIPARTIMENTO>
<DIPARTIMENTO Nome="Direzione">
<Indirizzo>Via Tito Livio, 27</Indirizzo>
<Citta>Milano</Citta>
</DIPARTIMENTO>
<DIPARTIMENTO Nome="Ricerca">
<Indirizzo>Via Morone, 6</Indirizzo>
<Citta>Milano</Citta>
</DIPARTIMENTO>
</DIPARTIMENTI>
</DATABASE>
La struttura ad albero del documento XML è la seguente:
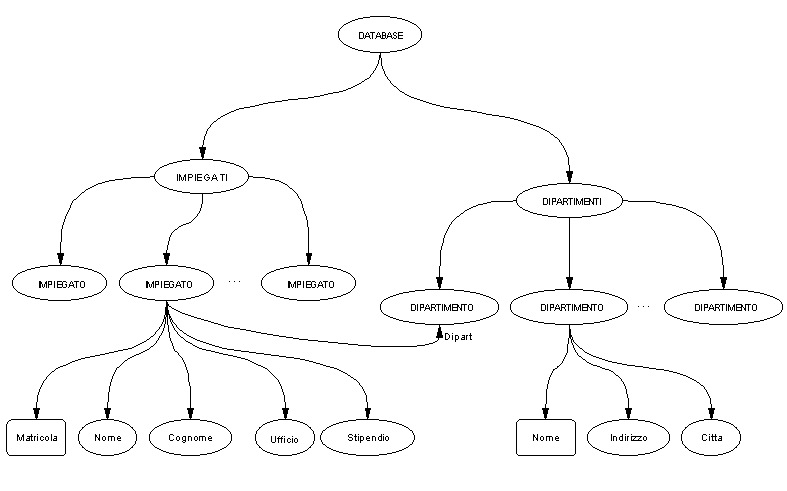 Dal grafo si nota che l’attributo Dipart dell’elemento IMPIEGATO è un riferimento ad uno degli elementi DIPARTIMENTO.
Dal grafo si nota che l’attributo Dipart dell’elemento IMPIEGATO è un riferimento ad uno degli elementi DIPARTIMENTO.
6.2.4 Foglio di stile per la visualizzazione dei dati
Vediamo, infine, il foglio di stile "DB.xsl", al quale è associato il documento XML. Esso rappresenta i nostri dati mediante due tabelle identiche a quelle viste nel paragrafo precedente:
<?xml version="1.0"?>
<xsl:template xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<HTML>
<HEAD><TITLE>
Database</TITLE></HEAD><BODY>
<H3>IMPIEGATI</H3>
<TABLE BORDER="1"><TR>
<TD ALIGN="CENTER"><FONT FACE="ARIAL"><U>Matricola</U></FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Nome</FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Cognome</FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Dipart</FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Ufficio</FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Stipendio</FONT></TD>
</TR>
<TR>
<TD ALIGN="CENTER">
<xsl:for-each select="DATABASE/IMPIEGATI/IMPIEGATO">
<DIV><xsl:value-of select="@Matricola"/></DIV>
</xsl:for-each>
</TD>
<TD ALIGN="CENTER">
<xsl:for-each select="DATABASE/IMPIEGATI/IMPIEGATO">
<DIV><xsl:value-of select="Nome"/></DIV>
</xsl:for-each>
</TD>
<TD ALIGN="CENTER">
<xsl:for-each select="DATABASE/IMPIEGATI/IMPIEGATO">
<DIV><xsl:value-of select="Cognome"/></DIV>
</xsl:for-each>
</TD>
<TD ALIGN="CENTER">
<xsl:for-each select="DATABASE/IMPIEGATI/IMPIEGATO">
<DIV><xsl:value-of select="@Dipart"/></DIV>
</xsl:for-each>
</TD>
<TD ALIGN="CENTER">
<xsl:for-each select="DATABASE/IMPIEGATI/IMPIEGATO">
<DIV><xsl:value-of select="Ufficio"/></DIV>
</xsl:for-each>
</TD>
<TD ALIGN="CENTER">
<xsl:for-each select="DATABASE/IMPIEGATI/IMPIEGATO">
<DIV><xsl:value-of select="Stipendio"/></DIV>
</xsl:for-each>
</TD>
</TR></TABLE>
<H3>DIPARTIMENTI</H3>
<TABLE BORDER="1"><TR>
<TD ALIGN="CENTER"><FONT FACE="ARIAL"><U>Nome</U></FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Indirizzo</FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Città</FONT></TD>
</TR>
<TR>
<TD ALIGN="CENTER">
<xsl:for-each select="DATABASE/DIPARTIMENTI/DIPARTIMENTO">
<DIV><xsl:value-of select="@Nome"/></DIV>
</xsl:for-each>
</TD>
<TD ALIGN="CENTER">
<xsl:for-each select="DATABASE/DIPARTIMENTI/DIPARTIMENTO">
<DIV><xsl:value-of select="Indirizzo"/></DIV>
</xsl:for-each>
</TD>
<TD ALIGN="CENTER">
<xsl:for-each select="DATABASE/DIPARTIMENTI/DIPARTIMENTO">
<DIV><xsl:value-of select="Citta"/></DIV>
</xsl:for-each>
</TD>
</TR></TABLE>
</BODY>
</HTML>
</xsl:template>
6.3 Pattern di XSL
Occupiamoci ora di come utilizzare XSL per effettuare delle interrogazioni su una base di dati. Per prima cosa occorre introdurre gli operatori e i caratteri speciali che è possibile inserire nei pattern di XSL [36]:
|
Operatore |
Nome |
Significato |
|
/ |
Figlio |
Seleziona un figlio dell’elemento alla sua sinistra. Se è da solo, o all’inizio del pattern, rappresenta l’intero documento e alla sua destra deve comparire l’elemento radice. |
|
// |
Discendente ricorsivo |
Seleziona l’elemento alla sua destra tra tutti i discendenti (a qualsiasi profondità) dell’elemento alla sua sinistra |
|
. |
Contesto corrente |
Indica il contesto corrente. La sequenza "./" all’inizio del pattern si può sottintendere. |
|
.. |
Padre |
Seleziona il nodo padre del contesto corrente. |
|
* |
Jolly |
Seleziona il primo elemento disponibile, quando è possibile scegliere tra più elementi alla stessa profondità. |
|
@ |
Attributo |
Deve precedere il nome degli attributi, per distinguerli dagli elementi. |
|
[n] |
Indice |
Se ci sono più elementi con lo stesso nome e allo stesso livello, seleziona l’(n-1)esimo. |
|
[end()] |
Ultimo |
Se ci sono più elementi con lo stesso nome e allo stesso livello, seleziona l’ultimo. |
|
[espr] |
Espressione booleana |
Seleziona gli elementi per cui l’espressione booleana espr risulta vera. |
|
text() |
Testo |
Seleziona il contenuto testuale del nodo corrispondente al contesto corrente |
|
index() |
Valore dell’indice |
Seleziona l’indice dell’elemento corrispondente al contesto corrente. |
|
context() |
Contesto iniziale |
Fa riferimento al valore che aveva il contesto prima del pattern corrente. |
|
id( ID) |
Identificatore |
Seleziona l’elemento con ID come identificatore univoco. |
|
ancestor( pattern) |
Antenato |
Seleziona l’antenato più vicino al contesto corrente che soddisfi il pattern indicato. |
Vediamo ora gli operatori consentiti all’interno delle espressioni booleane:
|
Simbolo |
Operatore |
|
|
and o $and$ o && |
And |
|
|
or o $or$ o || |
Or |
|
|
not() o $not$ |
Not |
|
|
= o $eq$ |
Uguale |
|
|
$ieq$ |
Uguale indipendentemente dalle lettere maiuscole o minuscole |
|
|
Simbolo |
Operatore |
|
|
!= o $ne$ |
Diverso |
|
|
$ine$ |
Diverso indipendentemente dalle lettere maiuscole o minuscole |
|
|
$all$ |
Per ogni |
|
|
$any$ |
Esiste |
|
|
< o $lt$ |
Minore |
|
|
$ilt$ |
Minore indipendentemente dalle lettere maiuscole o minuscole |
|
|
<= o $le$ |
Minore o uguale |
|
|
$ile$ |
Minore o uguale indipendentemente dalle lettere maiuscole o minuscole |
|
|
> o $gt$ |
Maggiore |
|
|
$igt$ |
Maggiore indipendentemente dalle lettere maiuscole o minuscole |
|
|
>= o $ge$ |
Maggiore o uguale |
|
|
$ige$ |
Maggiore o uguale indipendentemente dalle lettere maiuscole o minuscole |
|
Per chiarire le idee, vediamo alcuni esempi di pattern, con riferimento al documento XML del
§ 6.2.3:
./
NomeSeleziona tutti gli elementi Nome a partire dal contesto corrente. È equivalente al pattern "Nome".
/
DATABASESeleziona la radice del documento. Se il contesto è lo stesso dell’inizio del documento, si può omettere l’operatore "/", come nel foglio di stile del paragrafo precedente.
//
NomeSeleziona tutti gli elementi Nome a qualunque profondità a partire dal contesto corrente.
IMPIEGATO
[@Dipart='Amministrazione']Seleziona gli elementi IMPIEGATO con l’attributo Dipart uguale ad Amministrazione.
IMPIEGATO
[@Dipart = //DIPARTIMENTO[2]/@Nome]Seleziona gli elementi IMPIEGATO con l’attributo Dipart uguale al valore dell’attributo Nome del terzo elemento DIPARTIMENTO.
*/*
Seleziona tutti gli elementi "nipoti" del contesto corrente.
*/@*
Seleziona tutti gli attributi "nipoti" del contesto corrente.
IMPIEGATO
/*[1]Seleziona i secondi elementi figli di IMPIEGATO, cioè gli elementi Cognome.
IMPIEGATO
/*[end()]Seleziona gli ultimi elementi figli di IMPIEGATO, cioè gli elementi Stipendio.
IMPIEGATO
[Cognome>='M']Seleziona i gli elementi IMPIEGATO, con il contenuto del sottoelemento Cognome che inizia per "M" o per una lettera successiva nell’ordine alfabetico.
6.4 Interrogazioni semplici con XSL
6.4.1 Interrogazione 1
Si deve individuare lo stipendio degli impiegati di cognome "Rossi" [3]. Il risultato è contenuto nella colonna Salario. L’interrogazione è realizzata dal seguente documento XSL:
<?xml version="1.0"?>
<xsl:template xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<HTML>
<HEAD><TITLE>
Query</TITLE></HEAD><BODY>
<TABLE BORDER="1"><TR>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Salario</FONT></TD>
</TR>
<TR>
<TD ALIGN="CENTER">
<xsl:for-each select="DATABASE/IMPIEGATI/IMPIEGATO[Cognome='Rossi']">
<DIV><xsl:value-of select="Stipendio"/></DIV>
</xsl:for-each>
</TD>
</TR></TABLE>
</BODY>
</HTML>
</xsl:template>
e l’output che si ottiene è:
| Salario |
|
45 80 |
6.4.2 Interrogazione 2
Si vogliono ottenere il nome ed il cognome degli impiegati che lavorano nell’ufficio "20" del dipartimento "Amministrazione". Il documento XSL realizza la query sfruttando l’operatore booleano "and" :
<?xml version="1.0"?>
<xsl:template xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<HTML>
<HEAD><TITLE>
Database</TITLE></HEAD><BODY>
<TABLE BORDER="1"><TR>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Nome</FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Cognome</FONT></TD>
</TR>
<TR>
<TD ALIGN="CENTER">
<DIV><xsl:value-of select="Nome"/></DIV>
</xsl:for-each>
</TD>
<TD ALIGN="CENTER">
<DIV><xsl:value-of select="Cognome"/></DIV>
</xsl:for-each>
</TD>
</TR></TABLE>
</BODY>
</HTML>
</xsl:template>
Si ottiene il seguente risultato:
| Nome |
Cognome |
|
Giuseppe |
Verdi |
6.4.3 Interrogazione 3
Si vogliono ottenere i nomi e i cognomi degli impiegati che lavorano nel dipartimento "Amministrazione" o nel dipartimento "Produzione". Applichiamo il seguente foglio di stile:
<?xml version="1.0"?>
<xsl:template xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<HTML>
<HEAD><TITLE>
Query</TITLE></HEAD><BODY>
<TABLE BORDER="1"><TR>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Nome</FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Cognome</FONT></TD>
</TR>
<TR>
<TD ALIGN="CENTER">
<DIV><xsl:value-of select="Nome"/></DIV>
</xsl:for-each>
</TD>
<TD ALIGN="CENTER">
<DIV><xsl:value-of select="Cognome"/></DIV>
</xsl:for-each>
</TD>
</TR></TABLE>
</BODY>
</HTML>
</xsl:template>
il risultato che si ottiene è:
|
Nome |
Cognome |
|
Mario Carlo Giuseppe Paola Marco |
Rossi Bianchi Verdi Borroni Franco |
6.5 Join di tabelle
6.5.1 Interrogazione 4
Il join è un operatore che correla dati in diverse tabelle, sulla base di valori uguali. Un’interrogazione che effettua un join sulle nostre due tabelle è: per ogni impiegato, trovare nome, cognome e città in cui lavora. La città viene reperita dalla tabella DIPARTIMENTI, grazie ai riferimenti ad essa che la tabella IMPIEGATI contiene nella colonna Dipart. Vediamo il foglio di stile XSL che realizza questa query:
<?xml version="1.0"?>
<xsl:template xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<HTML>
<HEAD><TITLE>
Query</TITLE></HEAD><BODY>
<TABLE BORDER="1"><TR>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Nome</FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Cognome</FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Città</FONT></TD>
</TR>
<TR>
<TD ALIGN="CENTER">
<xsl:for-each select="//IMPIEGATO">
<DIV><xsl:value-of select="Nome"/></DIV>
</xsl:for-each>
</TD>
<TD ALIGN="CENTER">
<xsl:for-each select="//IMPIEGATO">
<DIV><xsl:value-of select="Cognome"/></DIV>
</xsl:for-each>
</TD>
<TD ALIGN="CENTER">
<xsl:for-each select="//IMPIEGATO">
<DIV><xsl:value-of select="id(@Dipart)/Citta"/></DIV>
</xsl:for-each>
</TD>
</TR></TABLE>
</BODY>
</HTML>
</xsl:template>
Per realizzare il join abbiamo utilizzato l’operatore id, che realizza i riferimenti incrociati di XML introdotti nel § 4.2.1. Infatti, ciascun elemento IMPIEGATO fa riferimento ad un elemento DIPARTIMENTO tramite l’attributo Dipart, di tipo IDREF. Il pattern "id(@Dipart)" corrisponde esattamente all’elemento DIPARTIMENTO "puntato" da Dipart [36]. Per ottenere l’informazione che cerchiamo, cioè la città dove si trova il dipartimento in cui lavora l’impiegato, basta utilizzare il pattern "id(@Dipart)/Citta". Il risultato dell’interrogazione è:
| Nome |
Cognome |
Città |
|
Mario Carlo Giuseppe Franco Carlo Lorenzo Paola Marco |
Rossi Bianchi Verdi Neri Rossi Lanzi Borroni Franco |
Milano Torino Milano Roma Milano Milano Milano Torino |
6.5.2 Interrogazione 5 (Join completo)
Il join completo consiste nell’inserimento in un’unica tabella di tutti i dati delle due tabelle [3]. Nella nostra base di dati, ad ogni impiegato deve corrispondere un dipartimento, come risulta dallo schema/DTD, che prevede un attributo Dipart obbligatorio per ogni elemento IMPIEGATO. Questi attributi, come abbiamo visto, sono riferimenti ai vari elementi DIPARTIMENTO. Il riferimento inverso non esiste e, infatti, nella tabella DIPARTIMENTI, si trova il dipartimento "Ricerca", del quale non fa parte nessun impiegato (vedi § 6.2.3).
Per realizzare il join completo occorre, dunque, basarsi sulla tabella DIPARTIMENTI:
Questo procedimento è seguito dal seguente foglio di stile XSL:
<?xml version="1.0" ?>
<xsl:template xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<HTML>
<HEAD><TITLE>
Join</TITLE></HEAD><BODY>
<TABLE BORDER="1">
<TR>
<TD ALIGN="CENTER"><FONT FACE="ARIAL"><U>Dipartimento</U></FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Indirizzo</FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Città</FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Matricola</FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Nome</FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Cognome</FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Ufficio</FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Stipendio</FONT></TD>
</TR>
<xsl:for-each select="//DIPARTIMENTO">
<TR>
<TD ALIGN="CENTER"><xsl:value-of select="@Nome"/></TD>
<TD ALIGN="CENTER"><xsl:value-of select="Indirizzo"/></TD>
<TD ALIGN="CENTER"><xsl:value-of select="Citta"/></TD>
<TD ALIGN="CENTER">
<DIV><xsl:value-of select="@Matricola"/></DIV>
</xsl:for-each>
<TD ALIGN="CENTER">
<DIV><xsl:value-of select="Nome"/></DIV>
</xsl:for-each>
<TD ALIGN="CENTER">
<DIV><xsl:value-of select="Cognome"/></DIV>
</xsl:for-each>
<TD ALIGN="CENTER">
<DIV><xsl:value-of select="Ufficio"/></DIV>
</xsl:for-each></TD>
<TD ALIGN="CENTER">
<DIV><xsl:value-of select="Stipendio"/></DIV>
</xsl:for-each>
</TR>
</xsl:for-each>
</TABLE>
</BODY>
</HTML>
</xsl:template>
In questo caso, il riferimento deve essere "percorso al contrario": da Nome a Dipart, dunque non è possibile utilizzare l’operatore id(), ma occorre l’operatore context(), che corrisponde di volta in volta all’elemento DIPARTIMENTO selezionato dall’elemento xsl:for-each più esterno [36].
L’output che si ottiene è il seguente:
6.6 Interrogazioni di tipo matematico
6.6.1 Interrogazione 6
Trovare nome, cognome e stipendio degli impiegati che guadagnano più di 40 milioni [3]. Il documento XSL che esprime questa query è:
<?xml version="1.0"?>
<xsl:template xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<HTML>
<HEAD><TITLE>
Query</TITLE></HEAD><BODY>
<TABLE BORDER="1"><TR>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Nome</FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Cognome</FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Stipendio</FONT></TD>
</TR>
<TR>
<TD ALIGN="CENTER">
<xsl:for-each select="//IMPIEGATO[Stipendio>40]">
<DIV><xsl:value-of select="Nome"/></DIV>
</xsl:for-each>
</TD>
<TD ALIGN="CENTER">
<xsl:for-each select="//IMPIEGATO[Stipendio>40]">
<DIV><xsl:value-of select="Cognome"/></DIV>
</xsl:for-each>
</TD>
<TD ALIGN="CENTER">
<xsl:for-each select="//IMPIEGATO[Stipendio>40]">
<DIV>
<xsl:value-of select="Stipendio"/>
</DIV>
</xsl:for-each>
</TD>
</TR></TABLE>
</BODY>
</HTML>
</xsl:template>
e ci restituisce la seguente tabella:
| Nome |
Cognome |
Stipendio |
|
Mario Franco Carlo Lorenzo Marco |
Rossi Neri Rossi Lanzi Franco |
45 45 80 73 46 |
Si noti che non compaiono i due impiegati che hanno lo stipendio esattamente uguale e 40 milioni, cioè Giuseppe Verdi e Paola Borroni.
6.6.2 Interrogazione 7
Vediamo un’interrogazione in cui il foglio di stile deve effettuare dei calcoli: trovare lo stipendio mensile degli impiegati di cognome "Bianchi". Questo foglio di stile XSL mostra il risultato in lire, anziché in milioni:
<?xml version="1.0"?>
<xsl:template xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<HTML>
<HEAD><TITLE>
Query</TITLE></HEAD><BODY>
<TABLE BORDER="1"><TR>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Stipendio Mensile</FONT></TD>
</TR>
<TR>
<TD ALIGN="CENTER">
<xsl:for-each select="//IMPIEGATO[Cognome='Bianchi']/Stipendio">
<DIV><xsl:eval>
</xsl:eval></DIV>
</xsl:for-each>
</TD>
</TR></TABLE>
</BODY>
</HTML>
</xsl:template>
Per calcolare lo stipendio mensile, abbiamo fatto ricorso ad un brevissimo script, contenuto all’interno dell’elemento xsl:eval. Questo si basa sull’oggetto this che, nel nostro caso, è il nodo selezionato dall’elemento xsl:for-each in cui è contenuto xsl:eval [25]. Il nodo in questione è l’elemento Stipendio. Applicando ad esso la proprietà nodeTypedValue, estraiamo il suo valore numerico, che moltiplichiamo per un milione e dividiamo per dodici, proprio per ottenere lo stipendio mensile in lire [19].
Al valore numerico ottenuto abbiamo applicato, infine, il metodo formatNumber, che è uno dei metodi del modello XML DOM a poter essere richiamato direttamente da un foglio di stile XSL [37]. La stringa di formattazione "#,###" indica all’elaboratore XSL di rappresentare il numero dividendo le migliaia. Il separatore utilizzato (punto, virgola, ecc.) dipende dalle impostazioni internazionali del software o del sistema operativo.
Il risultato della query è:
| Stipendio Mensile |
|
3.000.000 |
infatti nella tabella IMPIEGATI c’è un solo impiegato di cognome "Bianchi", che guadagna 36 milioni all’anno (vedi § 6.2.3).
6.6.3 Interrogazione 8
Vediamo infine un’interrogazione in cui si effettuano operazioni su più dati della tabella: trovare la somma degli stipendi del dipartimento "Amministrazione" [3]. Il foglio di stile che la realizza è:
<?xml version="1.0"?>
<xsl:template xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<xsl:script>
function somma(
nodo){
totale=0;
for (i=stipendi.nextNode();i;i=stipendi.nextNode())
totale +=i.nodeTypedValue;
return formatNumber(totale*1000000,"#,###");
}
</xsl:script>
<HTML>
<HEAD><TITLE>Query</TITLE></HEAD>
<BODY>
<TABLE BORDER="1"><TR>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Somma stipendi</FONT></TD>
</TR>
<TR>
<TD ALIGN="CENTER">
<DIV><xsl:eval>somma(this)</xsl:eval></DIV>
</TD>
</TR></TABLE>
</BODY>
</HTML>
</xsl:template>
In questo caso il "cuore" dell’interrogazione è costituito da uno script, contenuto all’interno dell’apposito elemento xsl:script, equivalente al tag <SCRIPT> di HTML [36]. Lo script definisce la funzione somma, avente come parametro un generico nodo del documento XML. Essa:
L’output che si ottiene è:
| Somma stipendi |
|
125.000.000 |
6.7 Ordinamenti
XSL permette di ordinare i dati di un documento XML associando l’attributo order-by agli elementi xsl:for-each o xsl:apply-templates. Il valore di order-by è uguale al path dell’elemento o attributo che viene scelto come chiave per l’ordinamento, preceduto:
| dal segno più "+", se si desidera un ordinamento cresente; | |
| dal segno meno "-", se si desidera un ordinamento decrescente. |
È possibile specificare più chiavi di ordinamento separandole con un punto e virgola ";
" [25]. Le varie chiavi vengono elencate in ordine di importanza e ciascuna dev’essere preceduta dal segno "+" o "-", che definisce il tipo di ordinamento.6.7.1 Interrogazione 9
Vediamo un’interrogazione con ordinamento: restituire il contenuto della tabella IMPIEGATI ordinato in modo decrescente secondo la colonna Cognome (chiave principale) e in modo cresente secondo la colonna Nome (chiave secondaria) [3]. Il foglio di stile che occorre è il seguente:
<?xml version="1.0"?>
<xsl:template xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<HTML>
<HEAD><TITLE>
Ordinamento</TITLE></HEAD><BODY>
<TABLE BORDER="1"><TR>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Matricola</FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Nome</FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL"><U>Cognome</U></FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Dipart</FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Ufficio</FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Stipendio</FONT></TD>
</TR>
<TR>
<TD ALIGN="CENTER">
<xsl:for-each select="//IMPIEGATO" order-by="-Cognome; +Nome">
<DIV><xsl:value-of select="@Matricola"/></DIV>
</xsl:for-each>
</TD>
<TD ALIGN="CENTER">
<xsl:for-each select="//IMPIEGATO" order-by="-Cognome; +Nome">
<DIV><xsl:value-of select="Nome"/></DIV>
</xsl:for-each>
</TD>
<TD ALIGN="CENTER">
<xsl:for-each select="//IMPIEGATO" order-by="-Cognome; +Nome">
<DIV><xsl:value-of select="Cognome"/></DIV>
</xsl:for-each>
</TD>
<TD ALIGN="CENTER">
<xsl:for-each select="//IMPIEGATO" order-by="-Cognome; +Nome">
<DIV><xsl:value-of select="@Dipart"/></DIV>
</xsl:for-each>
</TD>
<TD ALIGN="CENTER">
<xsl:for-each select="//IMPIEGATO" order-by="-Cognome; +Nome">
<DIV><xsl:value-of select="Ufficio"/></DIV>
</xsl:for-each>
</TD>
<TD ALIGN="CENTER">
<xsl:for-each select="//IMPIEGATO" order-by="-Cognome; +Nome">
<DIV><xsl:value-of select="Stipendio"/></DIV>
</xsl:for-each>
</TD>
</TR></TABLE>
</BODY>
</HTML>
</xsl:template>
Il risultato è:
| Matricola |
Nome |
Cognome |
Dipart |
Ufficio |
Stipendio |
|
VRDGSP RSSCRL RSSMRA NREFRN LNZLRN FRNMRC BRRPLA BNCCRL |
Giuseppe Carlo Mario Franco Lorenzo Marco Paola Carlo |
Verdi Rossi Rossi Neri Lanzi Franco Borroni Bianchi |
Amministrazione Direzione Amministrazione Distribuzione Direzione Produzione Amministrazione Produzione |
20 14 10 16 7 20 75 20 |
40 80 45 45 73 46 40 36 |
6.7.2 Interrogazione 10
Passiamo ad un’interrogazione più complessa: ordinare i dipartimenti in modo discendente in base alla somma degli stipendi pagati. In questo caso occorrono due documenti XSL. Il primo realizza una vista delle due tabelle della base di dati, in cui compaiono solamente il nome e la somma degli stipendi pagati agli impiegati di ciascun dipartimento:
<?xml version="1.0"?>
<xsl:template xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<xsl:script>
function somma(
nodo){
totale=0;
path = "//IMPIEGATO[@Dipart ='"+nodo.text+"']/Stipendio";
stipendi = nodo.selectNodes(path);
for (i=stipendi.nextNode();i;i=stipendi.nextNode())
totale +=i.nodeTypedValue;
return formatNumber(totale*1000000,"#,##0")
}
</xsl:script>
<xsl:pi name="xml-stylesheet">
<xsl:attribute name="type">text/xsl</xsl:attribute>
<xsl:attribute name="href">Query26b.xsl</xsl:attribute>
</xsl:pi>
<xsl:element name="VISTA">
<xsl:for-each select="//DIPARTIMENTO/@Nome">
<xsl:element name="DIPARTIMENTO">
<xsl:element name="Nome"><xsl:value-of/></xsl:element>
<xsl:element name="SommaSt">
<xsl:eval>somma(this)</xsl:eval>
</xsl:element>
</xsl:element>
</xsl:for-each>
</xsl:element>
</xsl:template>
Abbiamo fatto qualche modifica alla funzione somma del paragrafo scorso, per permetterle di calcolare le somme degli stipendi di tutti i dipartimenti. In particolare, abbiamo estratto i nomi di ciascun dipartimento dai nodi che li contengono grazie alla proprietà text [19]. Inoltre, abbiamo cambiato la stringa di formattazione in "#,##0", per mostrare il valore nullo relativo al dipartimento "Ricerca" [37].
Il risultato di questo foglio di stile è il seguente documento XML, ottenuto con il metodo spiegato nel § 5.7:
<?xml-stylesheet type="text/xsl" href="
Query26b.xsl"?><VISTA>
<DIPARTIMENTO>
<Nome>Amministrazione</Nome>
<SommaSt>
125.000.000
</SommaSt>
</DIPARTIMENTO>
<DIPARTIMENTO>
<Nome>Produzione</Nome>
<SommaSt>
82.000.000
</SommaSt>
</DIPARTIMENTO>
<DIPARTIMENTO>
<Nome>Distribuzione</Nome>
<SommaSt>
45.000.000
</SommaSt>
</DIPARTIMENTO>
<DIPARTIMENTO>
<Nome>Direzione</Nome>
<SommaSt>
153.000.000
</SommaSt>
</DIPARTIMENTO>
<DIPARTIMENTO>
<Nome>Ricerca</Nome>
<SommaSt>
0
</SommaSt>
</DIPARTIMENTO>
</VISTA>
Questo documento realizza la vista e ad esso bisogna applicare un altro foglio di stile per avere il risultato dell’interrogazione. Tale foglio di stile è indicato con il nome "Query26b.xsl" ed è:
<?xml version="1.0"?>
<xsl:template xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<HTML>
<HEAD><TITLE>
Ordinamento</TITLE></HEAD><BODY>
<TABLE BORDER="1"><TR>
<TD ALIGN="CENTER"><FONT FACE="ARIAL">Dipartimenti</FONT></TD>
<TD ALIGN="CENTER"><FONT FACE="ARIAL"><U>Somma stipendi</U></FONT></TD>
</TR>
<TR>
<TD ALIGN="CENTER">
<xsl:for-each select="VISTA/DIPARTIMENTO" order-by="-number(SommaSt)">
<DIV><xsl:value-of select="Nome"/></DIV>
</xsl:for-each>
</TD>
<TD ALIGN="CENTER">
<xsl:for-each select="VISTA/DIPARTIMENTO" order-by="-number(SommaSt)">
<DIV><xsl:value-of select="SommaSt"/></DIV>
</xsl:for-each>
</TD>
</TR></TABLE>
</BODY>
</HTML>
</xsl:template>
Si noti la presenza del metodo number nel valore dell’attributo order-by. I metodi number e date possono essere utilizzati per ordinare numeri e date, nel caso questi non siano "tipizzati" tramite lo spazio dei nomi datatypes [25]. Questo è il caso della nostra vista, che è priva sia dello schema, sia della dichiarazione di tale spazio dei nomi.
Finalmente, applicando alla vista il secondo foglio di stile, otteniamo il risultato dell’interrogazione:
| Dipartimenti |
Somma stipendi |
|
Direzione Amministrazione Produzione Distribuzione Ricerca |
153.000.000 125.000.000 82.000.000 45.000.000 0 |
6.8 Costrutti condizionali di XSL
Il linguaggio XSL, oltre all’ordinamento e al filtraggio dei dati, consente di effettuare test condizionali su di essi, utilizzando gli elementi xsl:if, xsl:choose, xsl:when ed xsl:otherwise [19].
6.8.1 Utilizzo dell’elemento xsl:if
L’elemento xsl:if effettua il test di esistenza sul pattern contenuto nel suo attributo test [36]. Se il pattern supera il test, entra a far parte dell’output il contenuto di xsl:if, viceversa questa parte di documento viene ignorata. Il pattern deve contenere un’espressione booleana racchiusa tra parentesi quadre, secondo la sintassi vista nel § 6.3. Se si vuole effettuare un test a partire dal contesto corrente, non è possibile sottintendere l’operatore "." che lo rappresenta.
Vediamo, ad esempio, un foglio di stile che elenca in ordine alfabetico gli impiegati del documento XML del § 6.2.3, contrassegnando con un asterisco quelli appartenenti al dipartimento "Amministrazione" [25]:
<?xml version="1.0"?>
<xsl:template xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<HTML>
<HEAD><TITLE>
Elenco impiegati</TITLE></HEAD><BODY>
<H1>Impiegati <SMALL>(in ordine alfabetico)</SMALL>:</H1>
<xsl:for-each select="//IMPIEGATO" order-by="+Cognome; +Nome">
<DIV>
<I><xsl:value-of select="Cognome"/>
<xsl:value-of select="Nome"/></I>
<xsl:if test=".[@Dipart='Amministrazione']">
<BIG>*</BIG>
</xsl:if>
</DIV>
</xsl:for-each>
<P><BIG>*</BIG>
Impiegati appartenenti al dipartimento "Amministrazione".
</P>
</BODY>
</HTML>
</xsl:template>
La visualizzazione che si ottiene è:
Bianchi Carlo
Borroni Paola *
Franco Marco
Lanzi Lorenzo
Neri Franco
Rossi Carlo
Rossi Mario *
Verdi Giuseppe *
*
Impiegati appartenenti al dipartimento "Amministrazione".6.8.2 Utilizzo dell’elemento xsl:choose
L’elemento xsl:choose consente di verificare contemporaneamente più condizioni e controllare l’output in base al risultato [19]. Grazie ad esso è possibile impostare relazioni condizionali analoghe ai costrutti "if-then-else" e "case of" presenti in molti linguaggi di programmazione. Tali relazioni si realizzano in combinazione con gli elementi xsl:when ed xsl:otherwise (facoltativo) secondo questa sintassi [25]:
<xsl:choose>
<xsl:when test="condizione_1">
contenuto_1</xsl:when><xsl:when test="condizione_2">contenuto_2</xsl:when>
[…]
<xsl:when test="condizione_n">
contenuto_n</xsl:when><xsl:otherwise>contenuto_0</xsl:otherwise>
</xsl:choose>
L’elaboratore XSL agisce in questo modo:
| valuta l’espressione booleana condizione_1: |
| se è vera, inserisce contenuto_1 nell’output e passa agli elementi del foglio di stile posti dopo il tag di chiusura di xsl:choose; | |
| se è falsa valuta condizione_2. |
| Ripete il procedimento per gli altri elementi xsl:when e, solo se tutte le condizoni sono false, inserisce nell’output contenuto_0, se presente. |
Il seguente foglio di stile utilizza l’elemento xsl:choose
per evidenziare con colori diversi gli impiegati appartenenti ai vari dipartimenti:<?xml version="1.0"?>
<xsl:template xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<HTML>
<HEAD><TITLE>
Elenco impiegati</TITLE></HEAD><BODY>
<H1>Impiegati <SMALL>(in ordine alfabetico)</SMALL>:</H1>
<TABLE>
<xsl:for-each select="//IMPIEGATO" order-by="+Cognome; +Nome">
<TR><xsl:attribute name="BGCOLOR">
<xsl:choose>
<xsl:when test=".[@Dipart='Amministrazione']">
</xsl:when>
<xsl:when test=".[@Dipart='Direzione']">cyan</xsl:when>
<xsl:when test=".[@Dipart='Produzione']">lightgreen</xsl:when>
<xsl:otherwise>yellow</xsl:otherwise>
</xsl:choose>
</xsl:attribute>
<TD><I>
<xsl:value-of select="Cognome"/>
<xsl:value-of select="Nome"/>
</I></TD></TR>
</xsl:for-each>
</TABLE>
<P/>
<DIV>
I colori indicano il dipartimento di appartenenza degli impiegati:
</DIV>
<TABLE><TR>
<TD BGCOLOR="lightcoral">Amministrazione</TD>
<TD BGCOLOR="cyan">Direzione</TD>
<TD BGCOLOR="lightgreen">Produzione</TD>
<TD BGCOLOR="yellow">Altri dipartimenti</TD>
</TR></TABLE>
</BODY>
</HTML>
</xsl:template>
L’output prodotto è questo:
6.9 Conclusioni
Tutti i fogli di stile mostrati in questo e nel precedente capitolo si basano essenzialmente sulla bozza di lavoro di XSLT del 16 dicembre 1998, che è quella supportata da Explorer 5. Da allora il linguaggio XSL si è evoluto ancora, pur senza raggiungere una versione definitva. Tralasciando gli oggetti di formattazione, ai quali abbiamo accennato nel § 5.9, le attuali specifiche riguardanti XSL sono due:
Una delle differenze principali fra i documenti XSL visti finora e le specifiche del W3C è nella realizzazione degli ordinamenti. La specifica prevede l’elemento xsl:sort, dotato di un proprio attributo select, al posto dell’attributo order-by [25].
Per fare un esempio, vediamo un frammento di un foglio di stile visto nel § 6.7.2:
<xsl:for-each select="
VISTA/DIPARTIMENTO" order-by="-number(SommaSt)"><DIV><xsl:value-of select="Nome"/></DIV>
</xsl:for-each>
secondo la specifica del W3C, occorre modificarlo in questo modo [26]:
<xsl:for-each select="
VISTA/DIPARTIMENTO"><xsl:sort select="SommaSt" data-type="number" order="descending"/>
<DIV><xsl:value-of select="Nome"/></DIV>
</xsl:for-each>
dove:
| data-type="number" indica che l’ordinamento dev’essere fatto considerando i dati come valori numerici, piuttosto che come stringhe; | |
| order="descending" indica che l’ordinamento dev’essere decrescente. |
Nel caso si debbano utilizzare più chiavi per l’ordinamento, il primo elemento xsl:sort
indicherà la chiave principale, il secondo la chiave secondaria, e così via.Oltre a questa differenza, l’ultima bozza di XSLT prevede numerosi elementi in più rispetto a quelli che abbiamo introdotto. Tra questi, vale la pena di citare xsl:output, che consente di definire il risultato dell’applicazione del foglio di stile al documento XML. Utilizzando:
| <xsl:output method="html"/> avremo un documento HTML come output; |
| <xsl:output method="xml"/> |
| <xsl:output method="text"/> |
L’elemento xsl:output
va inserito subito dopo la dichiarazione dello spazio dei nomi di XSL.Passiamo ora all’XML Path Language, noto con l’abbreviazione XPath [38]. Esso non è un’applicazione XML, come XSL o XML-Data, ma un linguaggio che definisce i pattern per indirizzare le parti di un documento XML. XPath è stato progettato per essere utilizzato sia con XSL che con XPointer e dispone di due sintassi: una estesa ed una abbreviata. La sintassi abbreviata, più semplice da utilizzare, è costituita sostanzialmente dagli operatori introdotti nel § 6.3.
Una modifica importante portata dalle ultime bozze di lavoro è nella numerazione degli indici degli elementi "fratelli" dotati dello stesso nome. In precedenza, tale numerazione partiva da 0, mentre l’ultima specifica del W3C la fa iniziare da 1. Pertanto, il pattern:
DOCENTI/PERSONA[2]
che compare negli esempi del § 5.8, dovrebbe selezionare il secondo elemento PERSONA all’interno di DOCENTI, e non il terzo, come fa l’elaboratore XSL contenuto in Explorer 5, al quale abbiamo fatto riferimento.
Gli esperti del W3C stanno lavorando da ormai più di due anni su XSL, XSLT ed XPath ma, per il momento, non esistono ancora versioni definitive di tali linguaggi. È auspicabile che le specifiche finali non siano più complesse delle attuali. Infatti bisogna tener presente che il successo di HTML è dovuto principalmente alla sua semplicità; pertanto, associare un linguaggio per i fogli di stile troppo complicato ad XML potrebbe avere delle ripercussioni negative per la diffusione di quest’ultimo su Web.
7 XLINK, XPOINTER E MATHML
7.1 XLink
L’XML Linking Language, noto con l’abbreviazione di XLink, è un linguaggio in grado di descrivere sia i collegamenti semplici e unidirezionali di HTML, sia collegamenti più sofisticati, utilizzando la sintassi di XML [39]. Il markup di XLink è realizzato per essere inserito sia negli schemi che nelle istanze dei documenti XML.
Così come XSL, anche XLink è associato ad uno spazio dei nomi, che è:
http://www.w3.org/XML/XLink/0.9
e dev’essere dichiarato esplicitamente nel documento. Solitamente il prefisso utilizzato è "xlink". Pertanto, se si intende utilizzare XLink dovrà comparire la seguente dichiarazione di spazio dei nomi:
<ELEMENTO xmlns:xlink="http://www.w3.org/XML/XLink/0.9">
[…]
</ELEMENTO>
ELEMENTO
dev’essere la radice del documento o, quantomeno, un elemento che comprenda al suo interno tutti i link.XLink permette di scegliere come definire i collegamenti:
In questa tabella sono elencati gli elementi di XLink ed i valori corrispondenti da assegnare a xlink:type nel caso si vogliano inserire i collegamenti in elementi qualunque di XML:
|
Elemento |
Attributo equivalente |
Significato |
|
xlink:simple |
xlink:type="simple" |
Collegamento semplice (vedi § 7.2) |
|
xlink:extended |
xlink:type="extended" |
Collegamento esteso (vedi § 7.3) |
|
xlink:arc |
xlink:type="arc" |
Arco (vedi § 7.3) |
|
xlink:locator |
xlink:type="locator" |
Localizzatore (vedi § 7.3) |
|
xlink:group |
Gruppo di collegamenti estesi (vedi § 7.4) |
|
|
xlink:document |
Localizzatore di un documento appartenente ad un gruppo di collegamenti estesi (vedi § 7.4) |
7.2 Collegamenti semplici
Iniziamo dai collegamenti semplici. Essi sono analoghi a quelli realizzati dal tag <A> di HTML, come questo:
<A HREF="
http://space.tin.it/io/lucposti/">Home page di Luca Postiglione</A>La conversione in XLink di tale collegamento è:
<xlink:simple href="
http://space.tin.it/io/lucposti/">Home page di Luca Postiglione
</xlink:simple>
Lo stesso collegamento, inserito in un elemento XML definito da noi, diventa:
<Ancora xlink:type="simple" xlink:href="
http://space.tin.it/io/lucposti/">Home page di Luca Postiglione
</Ancora>
Si noti che l’attributo href dev’essere dichiarato appartenente allo spazio dei nomi di XLink. In generale, gli attributi di XLink:
| non hanno bisogno del prefisso "xlink", se utilizzati in un elemento di XLink, il cui nome già contiene tale prefisso; | |
| richiedono il prefisso "xlink", se presenti in altri elementi. |
Passiamo alla descrizione degli attributi previsti per i collegamenti semplici:
| href Indica il localizzatore della risorsa, in grado di identificare la risorsa alla quale il collegamento fa riferimento [19]. È l’unico attributo obbligatorio di un collegamento semplice. La sua sintassi è [43]: |
| role |
| title |
| show |
| actuate |
Vediamo un esempio di collegamento semplice in cui compaiono tutti gli attributi:
<DIPARTIMENTO xlink:type="simple"
xlink:href="
dipartimento.xml"xlink:role="list"
xlink:title="Informatica - Elenco docenti"
xlink:show="new"
xlink:actuate="user">
Elenco dei docenti del Dipartimento di Informatica
</DIPARTIMENTO>
alternativamente, usando l’elemento xlink:simple, lo stesso collegamento diventa:
<xlink:simple href="
dipartimento.xml"role="list"
title="Informatica - Elenco docenti"
show="new"
actuate="user">
Elenco dei docenti del Dipartimento di Informatica
</xlink:simple>
Questo è un collegamento al file "dipartimento.xml", che viene indicato al browser come una risorsa di tipo "list". Essa, invece, è indicata all’utente con il titolo "Informatica – Elenco docenti". Questo titolo può, ad esempio, comparire accanto al puntatore del mouse quando passa sopra la visualizzazione data al link dal foglio di stile. Infine, il collegamento sarà attuato aprendo la risorsa in una nuova finestra solo quando l’utente lo attiverà, cliccando il mouse sulla sua rappresentazione [40].
7.3 Collegamenti estesi
7.3.1 Sintassi
Un collegamento esteso si differenzia da un collegamento semplice, in quanto è in grado di collegare un numero qualsiasi di risorse, sia locali che remote [39]. Ciascun collegamento esteso è costituito da un elemento xlink:extended, che può avere come figli localizzatori (xlink:locator) ed archi (xlink:arc). Vediamo in dettaglio il significato e gli attributi supportati da questi tre elementi:
| xlink:extended |
| role e title, già visti per i collegamenti semplici; | |
| showdefault ed actuatedefault: definiscono i valori di default degli attributi show ed actuate per tutti gli archi del collegamento esteso. Non hanno valori predefiniti. |
Non ammette l’attributo href
, riservato agli elementi xlink:locator.| xlink:locator |
| id (obbligatorio): è un identificatore univoco assegnato alla risorsa, che può essere utilizzato dagli archi per individuare le varie risorse. È un attributo di tipo "ID" (vedi § 4.2.1). | |
| role e title. |
| xlink:arc |
| from e to: sono attributi obbligatori di tipo "IDREF" (vedi § 4.2.1). Indicano rispettivamente la risorsa di origine e di destinazione dell’arco, facendo riferimento agli attributi id dei localizzatori. | |
| show ed actuate, già visti per i collegamenti semplici. Se questi attributi sono presenti, l’attraversamento associato all’arco è eseguito nel modo definito dai loro valori; viceversa si utilizzano i valori degli attributi showdefault ed actuatedefault dell’elemento "padre" xlink:extended. |
7.3.2 Introduzione degli archi nei collegamenti estesi
Gli archi sono la grande novità dell’ultima bozza di lavoro su XLink del W3C, datata 26 luglio 1999. In precedenza, i collegamenti estesi contenevano esclusivamente i localizzatori e si presentavano in questo modo (anche se con una sintassi diversa) [41]:
<Esempi xlink:type="extended">
<Collegamenti xlink:type="locator"
xlink:href="
Elink.xml"xlink:role="source"/>
<Dipartimento xlink:type="locator"
xlink:href="Dipartimento.xml"
xlink:role="code"/>
<Database xlink:type="locator"
xlink:href="DB.xml"
xlink:role="code"/>
</Esempi>
Questo markup non specifica il tipo di connessione che deve esistere fra i tre localizzatori. Ciò significa che il browser dev’essere in grado di supportare tutti i possibili collegamenti fra le risorse, anche quelli che, magari, sono ritenuti superflui da chi ha scritto il collegamento esteso. Rappresentiamo la situazione in questo grafo, che raffigura le risorse come nodi e i collegamenti come archi:
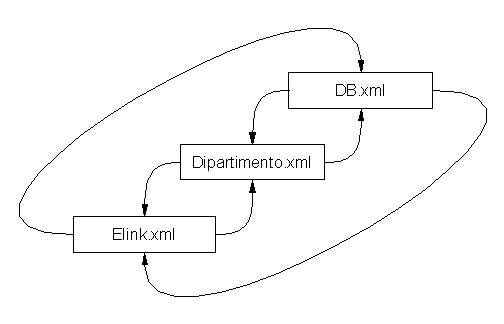
Come vediamo dal grafo, gli attraversamenti fra le risorse sono sei; essi, però, diventano addirittura nove se includiamo i collegamenti di ciascuna risorsa con se stessa, teoricamente possibili. In generale, se il collegamento esteso comprende n risorse, gli attraversamenti da gestire sono n2. In questa situazione il browser deve fare affidamento solo sul valore dell’attributo role, che definisce la funzione di ciascuna risorsa e permette di trascurare eventuali link privi di significato.
Viceversa, gli archi consentono all’autore del documento di specificare i link che egli ritiene utili, riducendo notevolmente il tempo di elaborazione. Torniamo al nostro esempio, e supponiamo che ci interessino solamente i due attraversamenti dalla risorsa locale "Elink.xml" alle altre due risorse (remote). Il collegamento esteso diventa:
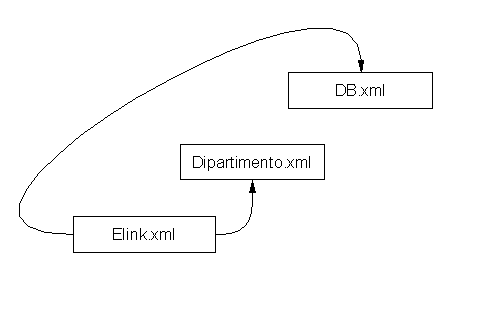
ed il markup che lo descrive è il seguente:
<Esempi xlink:type="extended">
<Collegamenti xlink:type="locator"
xlink:href="
Elink.xml"xlink:id="menu"/>
<Dipartimento xlink:type="locator"
xlink:href="Dipartimento.xml"
xlink:id="esempio1"/>
<Database xlink:type="locator"
xlink:href="DB.xml"
xlink:id="esempio2"/>
<Link1 xlink:type="arc" xlink:from="menu" xlink:to="esempio1"/>
<Link2 xlink:type="arc" xlink:from="menu" xlink:to="esempio2"/>
</Esempi>
Il browser deve essere in grado, comunque, di attivare su richiesta dell’utente anche i collegamenti non previsti dall’autore del documento, chiamati archi impliciti [39].
XLink non è al momento supportato né da Explorer 5, né da altre applicazioni commerciali [42]. Inoltre, l’introduzione degli archi e il cambiamento della sintassi hanno reso obsoleti tutti i programmi sperimentali basati sulla versione di XLink del marzo 1998, tra i quali possiamo citare il browser "HyBrick", prodotto dalla Fujitsu. Gli esempi su XLink sono ricavati direttamente dalla specifica, e non è detto che funzioneranno sui futuri browser compatibili con questo linguaggio.
7.4 Gruppi di collegamenti estesi
Un gruppo di collegamenti estesi è un elemento contenente un elenco di riferimenti a documenti correlati fra loro [19]. Due documenti "fileA.xml" e "fileB.xml" sono correlati se "fileA.xml" contiene dei link estesi che fanno riferimento a "fileB.xml" e/o viceversa [40].
Il gruppo di collegamenti estesi è realizzato in XLink dall’elemento xlink:group [39]. Esso ha come figli un numero qualsiasi (al limite anche zero) di elementi xlink:document, ciascuno dei quali individua, grazie all’attributo obbligatorio href, uno dei documenti correlati.
Questo costrutto di XLink indica al browser di elaborare insieme tutti i documenti correlati e di attivare i collegamenti in essi presenti [1]. Alcuni possibili risultati sono:
L’elemento xlink:group può contenere l’attributo steps, il cui valore è un numero intero che indica al browser quanti livelli di collegamenti estesi esso debba risolvere per completare l’elenco dei link del gruppo [40]. Per chiarire meglio questo concetto vediamo un esempio [39]:
<xlink:group steps="2"> <xlink:document href="fileA.xml"/> <xlink:document href="fileB.xml"/> <xlink:document href="fileC.xml"/> </xlink:group>
Supponiamo di voler costruire un elenco dei link contenuti nei tre documenti XML correlati "fileA.xml", "fileB.xml" e "fileC.xml". È possibile che questi file contengano a loro volta gruppi di collegamenti estesi riferiti a documenti con al loro interno ulteriori gruppi di collegamenti, e così via. In un caso simile diventa praticamente impossibile ottenere l’elenco di link desiderato.
L’attributo steps impedisce questo processo potenzialmente infinito, specificando quanti livelli di gruppi di collegamenti elaborare [19]. Il seguente schema, riferito al nostro esempio, mostra i file di cui occorre elaborare i collegamenti, a seconda dei valori di steps:
Poiché steps ha valore "2", il browser deve comporre la lista dei collegamenti estesi presenti nei file contenuti all’interno dell’ellisse rosso, ignorando gli altri documenti correlati. Si noti, infine, che gli altri valori di steps presenti negli elementi xlink:group dei documenti correlati al documento iniziale sono ignorati.
7.5 Cenni sul linguaggio XPointer
7.5.1 Compatibilità con XPath
L’XML Pointer Language, chiamato per praticità XPointer, indirizza le parti interne di un documento XML, utilizzando delle opportune estensioni all’URI del documento [1]. Queste, come abbiamo accennato nel § 7.2, si trovano dopo l’URI, e seguono la sintassi [43]:
URI
#xptr(Xpointer)In particolare, XPointer permette il riferimento ad elementi (dotati o meno di un identificatore univoco), attributi e stringhe di testo di un documento XML.
L’ultima bozza di lavoro di XPointer è stata pubblicata il 9 luglio 1999 dal W3C e si differenzia sensibilmente dalla precedente, del luglio 1997, in quanto la sintassi delle espressioni di XPointer è stata resa compatibile con XPath, il linguaggio che definisce i pattern di indirizzamento utilizzati da XSL. Pertanto, attualmente, non esistono ancora programmi che supportino quest’ultima versione di XPointer e non necessariamente gli esempi riportati funzioneranno nei software futuri compatibli con tale linguaggio.
Abbiamo già elencato nel § 6.3 i principali operatori di XPath, introducendoli direttamente nella loro forma abbreviata. Vediamo alcuni esempi di localizzatori che fanno riferimento al file "DB.xml", che si trova nel § 6.2.3 [19]:
DB.xml
#xptr(/DATABASE/IMPIEGATI/IMPIEGATO[2])Indirizza il secondo tra gli elementi IMPIEGATO, figlio dell’elemento IMPIEGATI e nipote di DATABASE, che dev’essere la radice del documento. La numerazione degli elementi fratelli con lo stesso nome parte da 1, come nella specifica di XPath (vedi § 6.9).
DB.xml
#xptr(id(’Amministrazione’))Indirizza l’elemento avente "Amministrazione" come identificatore univoco, cioè il primo elemento DIPARTIMENTO.
DB.xml
#xptr(//IMPIEGATO/@Nome)Indirizza l’attributo Nome del primo elemento IMPIEGATO trovato nel documento a qualsiasi livello.
DB.xml
#xptr(//IMPIEGATO[@Dipart='Amministrazione'])Indirizza il primo elemento IMPIEGATO con l’attributo Dipart uguale ad Amministrazione.
Si noti che XPointer indirizza solo la prima parte di documento rispondente alle caratteristiche del pattern. In questo senso, il suo funzionamento è più simile a quello dell’elemento xsl:value-of (vedi § 5.1), che a quello dell’elemento xsl:for-each, che seleziona tutte le parti di documento che soddisfano il pattern (vedi § 5.2).
7.5.2 Selezione di un gruppo di elementi
Occupiamoci ora di alcune caratteristiche che XPointer aggiunge ad XPath. Iniziamo dal termine range, la cui sintassi è [43]:
range::inizio,fine
Esso indirizza un sottoinsieme del documento XML che parte dalla locazione corrispondente al pattern inizio e termina in quella corrispondente al pattern fine.
Vediamo un esempio:
DB.xml
#xptr(id(‘NREFRN’)/range::*[1],*[3])Indirizza i primi tre figli dell’elemento avente "NREFRN" come identificatore univoco. Gli elementi selezionati sono NOME, COGNOME ed UFFICIO corrispondenti all’impiegato "Franco Neri", la cui matricola è, appunto, "NREFRN" (vedi § 6.2.3).
7.5.3 Selezione di stringhe
Il termine string indirizza una stringa all’interno del testo di un documento XML, ignorando il markup. Esso ha la seguente sintassi:
string::occorrenza,stringa,posizione,lunghezza
dove:
| occorrenza (obbligatorio): stabilisce quale occorrenza di stringa debba essere cercata. | |
| stringa (obbligatorio): definisce la stringa da cercare. In caso di stringa vuota, viene cercato l’n-esimo carattere del testo, con n posto uguale al valore di occorrenza. | |
| posizione: definisce la posizione da cui far iniziare l’indirizzamento. Si assume come riferimento la stringa selezionata dalla coppia di parametri occorrenza,stringa. |
| Se il valore è un numero positivo n, l’indirizzamento parte dall’n-esimo carattere di tale stringa. | |
| Se il valore è un numero negativo -n, l’indirizzamento parte dall’n-esimo carattere a sinistra della fine della stringa. |
| lunghezza: indica il numero di caratteri da selezionare. Il valore di default è 1. |
Consideriamo ora il frammento del documento "Dipartimento.xml" del § 3.9 indirizzato dal localizzatore:
Dipartimento.xml
#xptr(/DOCENTI/PERSONA[3]/CURRICULUM)Esso è:
<CURRICULUM>
Nato nel 1971 e laureato nel 1998. Collabora con il prof. Brahms nel corso di Intelligenza artificiale.</CURRICULUM>e lo utilizziamo per mostrare alcuni esempi di indirizzamento di stringhe.
Dipartimento.xml
#xptr(/DOCENTI/PERSONA[3]/CURRICULUM/string::3,’’)Indirizza il terzo carattere del testo, che è "t".
Dipartimento.xml
#xptr(/DOCENTI/PERSONA[3]/CURRICULUM/string::3,’nel’,5,5)Indirizza una stringa di cinque caratteri, presa dopo cinque caratteri a partire dalla terza occorrenza di "nel". Questa stringa è la parola "corso".
Dipartimento.xml
#xptr(/DOCENTI/PERSONA[3]/CURRICULUM/string::1,’.’,-5,4)Indirizza una stringa di quattro caratteri, scelta cinque caratteri a sinistra della fine dalla prima occorrenza del punto ".". Tale stringa è "1998".
La selezione delle stringhe effettuata da XPointer è sensibile alla differenza fra lettere maiuscole e minuscole, così come tutto il linguaggio XML. Pertanto se si cerca la stringa "intelligenza":
Dipartimento.xml
#xptr(/DOCENTI/PERSONA[3]/CURRICULUM/string::1,’intelligenza’) NO!
si avrà un errore, perche nel testo compare "Intelligenza" con la "I" maiuscola.
XPath ed XPointer hanno varie funzioni più avanzate di quelle viste in questo paragrafo e nel § 6.3, ma sono ancora in fase di sviluppo e potrebbero cambiare con le future bozze di lavoro [1]. Per questo motivo abbiamo presentato solo un’introduzione a questi due linguaggi, che evidenziasse i loro principi ed il loro funzionamento.
7.6 Prime applicazioni di XML
7.6.1 Vocabolari XML
XML può essere utilizzato per creare linguaggi di markup compatti e potenti, in grado di rispondere a qualunque esigenza di gestione e distribuzione di dati ed informazioni [5]. Tali linguaggi sono applicazioni XML, definite tramite particolari DTD e chiamate vocabolari XML [19]. Infatti, tutti questi linguaggi si differenziano per gli elementi e gli attributi che ne costituiscono il "vocabolario", ma hanno in comune la grammatica di XML, composta dalle regole sintattiche esposte nel capitolo 3.
Elenchiamo brevemente le più importanti applicazioni di XML finora definite:
| CDF (Channel Definition Format). Descrive il comportamento dei canali, pagine Web inviate su richiesta degli utenti ed aggiornate automaticamente con una certa frequenza. È una delle prime applicazioni XML, ed è supportata addirittura da Explorer 4. | |
| CML (Chemical Markup Language). È un linguaggio in grado di rappresentare disposizioni complesse di atomi e molecole e di gestire documenti di tipo scientifico [5]. | |
| SMIL (Synchronized Multimedia Integration Language). È un linguaggio di presentazione multimediale, sviluppato allo scopo di fornire uno standard per la sincronizzazione degli elementi multimediali all’interno di una pagina Web [19]. | |
| RDF (Resource Description Framework). Definisce i metadati, che descrivono in modo efficace le varie fonti di informazioni contenute nel Web, come documenti, immagini, ecc. [1]. | |
| SVG (Scalable Vector Graphics). È un linguaggio di codifica delle immagini vettoriali, in grado di consentirne la visualizzazione all’interno delle pagine Web [44]. | |
| XHTML (eXtensible HyperText Markup Language). Ridefinisce HTML come applicazione XML. È stato introdotto nel § 3.9. |
In questo elenco manca una delle applicazioni più interessanti a livello scientifco: MathML (Mathematical Markup Language), al quale è dedicato l’ultimo paragrafo della tesina.
7.6.2 Cenni sul linguaggio MathML
MathML è un linguaggio di markup basato su XML in grado di rappresentare su Web anche le formule matematiche più complesse [5]. Esso comprende numerosi elementi, attributi ed entità, orientati a definire sia il contenuto che la rappresentazione delle formule [45]. Il browser Amaya, realizzato dal W3C, supporta un sottoinsieme di MathML, costituito dagli elementi di presentazione [46]:
|
Tag |
Significato |
|
<math> |
Radice del documento MathML |
|
<mrow> |
Riga. Tutto il contenuto di questo tag dev’essere allineato orizzontalmente. |
|
<mi> |
Identificatore (variabile, costante, ecc.) |
|
<mn> |
Numero |
|
<mo> |
Operatore matematico |
|
<mroot> |
Radice |
|
<msqrt> |
Radice quadrata |
|
<mfrac> |
Frazione |
|
<msubsup> |
Apice e pedice |
|
<msup> |
Apice |
|
<msub> |
Pedice |
|
<munderover> |
Sovrascrittura e sottoscrittura |
|
<mover> |
Sovrascrittura |
|
<munder> |
Sottoscrittura |
|
<mmultiscripts> |
Espressioni con indici multipli |
|
<mtable> |
Matrice (analogo a <TABLE> di HTML). |
|
<mtr> |
Riga di una matrice (analogo a <TR> di HTML). |
|
<mtd> |
Elemento di una matrice (analogo a <TD> di HTML). |
In MathML l’inserimento dei simboli matematici viene effettuato tramite opportune entità. Per motivi di spazio, ne introduciamo solo alcune:
|
Entità |
Significato |
Simbolo |
|
&florin; |
Funzione di |
¦ |
|
∞ |
Infinito |
¥ |
|
∫ |
Integrale |
ò |
|
∑ |
Sommatoria |
S |
|
α |
Alfa minuscola (è disponibile tutto l’alfabeto greco) |
a |
|
∂ |
Derivata parziale |
¶ |
|
▿ |
Operatore nabla |
Ñ |
Vediamo un esempio di documento MathML:
<math><mrow>
<mo>&florin;
(</mo><mi>x</mi><mo>)=</mo><munderover>
<mo>∑</mo>
<mrow>
<mi>n</mi><mo>=</mo><mn>0</mn>
</mrow>
<mo>+∞</mo>
</munderover>
<mfrac>
<mrow>
<msup>
<mo>&florin;</mo>
<mrow>
<mo>(</mo><mi>n</mi><mo>)</mo>
</mrow>
</msup>
<mrow>
<mo>(</mo>
<msub><mi>x</mi> <mi>0</mi></msub>
<mo>)</mo>
</mrow>
</mrow>
<mrow>
<mi>n</mi><mo>!</mo>
</mrow>
</mfrac>
<msup>
<mrow>
<mo>(</mo><mi>x</mi><mo>-</mo>
<msub><mi>x</mi> <mi>0</mi></msub>
<mo>)</mo>
</mrow>
<mi>n</mi>
</msup>
</mrow></math>
Esso produce la formula dello sviluppo in serie di Taylor di una funzione ¦ (x), che Amaya mostra in questo modo:
Dal confronto fra il listato e il risultato ottenuto, MathML sembra un linguaggio fin troppo complicato. In realtà, il documento è così lungo perché è realizzato con i soli elementi di presentazione. MathML prevede numerosi altri elementi, chiamati elementi di contenuto, in grado di semplificare notevolmente la stesura delle formule matematiche [45]. Purtroppo essi non sono supportati dall’attuale versione di Amaya.
Appendice A: Guida rapida
In quest’appendice sono elencate brevemente le sintassi dei vari markup dei linguaggi XML, XSL, XLink, ecc. introdotti nella tesina. Per ognuno di essi sono riportati i paragrafi da consultare per maggiori informazioni.
XML
|
Elemento contenente un attributo: <Nome attributo=" valore">Contenuto</Nome> |
§ 3.2.1 |
|
Elemento vuoto: <Vuoto attributo=" valore"/> |
§ 3.2.1 |
|
Dichiarazione XML: ?>
|
§ 3.4.1 |
|
Dichiarazione di tipo di documento: <!DOCTYPE RADICE SYSTEM "Identificatore_di_sistema" [Sottoinsieme_interno_DTD]> |
§ 3.4.2 |
|
Dichiarazione di tipo di documento con identificatore pubblico: <!DOCTYPE RADICE PUBLIC "Identificatore_pubblico" "Identificatore_di_sistema" [Sottoinsieme_interno_DTD]> |
§ 3.4.2 |
|
Riferimento ad un entità generale: &Nome; |
§§ 3.5 e 4.3 |
|
Riferimento ad un carattere: &#Codice; oppure odice_hex; |
§ 3.6 |
|
Istruzione di elaborazione: <?Istruzione?> |
§ 3.7 |
|
Associazione ad un foglio di stile XSL: <?xml-stylesheet type="text/xsl" href=" documento.xsl"?> |
§ 3.7 |
|
Commento: <!-- Commento--> |
§ 3.8 |
|
Dichiarazione standard per uno spazio dei nomi: <ELEMENTO xmlns="URI"> |
§ 4.6 |
|
Dichiarazione esplicita per uno spazio dei nomi: <ELEMENTO xmlns:prefisso="URI"> |
§ 4.6 |
DTD
|
Dichiarazione di un elemento: <!ELEMENT NOME CONTENUTO> |
§ 4.1 |
|
Dichiarazione di un attributo: <!ATTLIST ELEMENTO NOME TIPO IMPOSTAZIONE> |
§ 4.2 |
|
Dichiarazione di un’entità generale: <!ENTITY Nome Definizione> |
§§ 4.3.1 e 4.3.2 |
|
Dichiarazione di un’entità parametro: <!ENTITY % Nome Definizione> |
§ 4.3.3 |
|
Riferimento ad un’entità parametro: %Nome; |
§ 4.3.3 |
|
Dichiarazione di un’entità esterna non analizzata: <!ENTITY Nome SYSTEM " nome_file" NDATA Annotazione> |
§ 4.4 |
|
Annotazione: <!NOTATION Annotazione Descrizione> |
§ 4.4 |
Spazi dei nomi
|
XSL: http://www.w3.org/TR/WD-xsl |
§ 5.1 |
|
XLink (non supportato da Explorer 5): http://www.w3.org/XML/XLink/0.9 |
§ 7.1 |
|
HTML: http://www.w3.org/TR/REC-html40 |
§ 4.6 |
|
XML-Data: urn:schemas-microsoft-com:xml-data |
§§ 4.7 e 6.1 |
|
Datatypes: urn:schemas-microsoft-com:datatypes |
§ 6.1 |
XML-Data
|
Schema di XML-Data: <Schema name="mio_schema"
xmlns="urn:schemas-microsoft-com:xml-data"
xmlns:dt="urn:schemas-microsoft-com:datatypes">
|
§§ 4.7.2 e 6.1 |
|
Associazione ad uno schema: <ELEMENTO xmlns="x-schema: schema.xml"> |
§ 4.7.2 |
|
Associazione di alcuni elementi ad uno schema: <ELEMENTO prefisso:xmlns="x-schema: schema.xml"> |
§ 4.7.2 |
|
Dichiarazione di un elemento: <ElementType name=" NOME" content="empty|textOnly|eltOnly|mixed"><element type="nome_figlio" minOccurs="min" maxOccurs="max" dt:type="tipo"/> [Eventuali riferimenti ad altri sottoelementi] <attribute type="ATTRIBUTO" required="yes|no" default="valore_di_default"/> [Eventuali riferimenti ad altri attributi] </ElementType> |
§§ 4.7 e 6.1 |
|
Dichiarazione di un attributo: <AttributeType name=" ATTRIBUTO"required="yes|no" default="valore_di_default" dt:type="tipo"/> |
§§ 4.7.4 e 6.1 |
|
Tipo di dati di un elemento o attributo: <datatype dt:type="tipo" /> |
§§ 6.1 e 6.1.1 |
XSLT
|
Foglio di stile: <xsl:stylesheet> |
§ 5.4 |
|
Modello: <xsl:template match="pattern"> |
§ 5.4 |
|
Applicazione degli altri modelli: <xsl:apply-templates select="pattern" order-by="chiavi"> |
§§ 5.4 e 6.7 |
|
Contenuto di un nodo: <xsl:value-of select="pattern"/> |
§ 5.1 |
|
Selezione di più nodi: <xsl:for-each select="pattern" order-by="chiavi"> |
§§ 5.2 e 6.7 |
|
Script: <xsl:script> |
§ 6.6.3 |
|
Valutazione di script: <xsl:eval> |
§§ 5.5 e 6.6 |
|
Nome di un nodo: <xsl:node-name/> |
§ 5.5 |
|
Copia di un nodo: <xsl:copy select="pattern"> |
§ 5.8.1 |
|
Generazione di un elemento: <xsl:element name="nome_elemento"> |
§ 5.8.2 |
|
Generazione di un attributo: <xsl:attribute name=" nome_attributo"> |
§ 5.8.2 |
|
Generazione di un’istruzione di elaborazione: <xsl:pi name="nome_pi"> |
§ 5.8.2 |
|
Generazione di un commento: <xsl:comment> |
§ 5.8.2 |
|
Costrutto condizionale "if": <xsl:if test="condizione"> |
§ 6.8.1 |
|
Costrutto condizionale "choose": <xsl:choose> <xsl:when test="condizione_1"> contenuto_1</xsl:when><xsl:when test="condizione_2">contenuto_2</xsl:when> […] <xsl:when test="condizione_n"> contenuto_n</xsl:when><xsl:otherwise>contenuto_0</xsl:otherwise> </xsl:choose> |
§ 6.8.2 |
|
Ordinamento (sostituito in Explorer 5 dall’attributo order-by ):<xsl:sort select="pattern" data-type="text|number" order="ascending|descending"/> |
§ 6.9 |
|
Risultato dell’applicazione del foglio di stile (non supportato da Explorer 5): <xsl:output method="html|xml|text"/> |
§ 6.9 |
XPath
I principali operatori di XPath sono elencati nella loro forma abbreviata nella tabella del § 6.3.
XLink (non supportato da Explorer 5)
|
Collegamento semplice: <xlink:simple href="localizzatore" role="significato" title=" titolo"show="replace|new|parsed" actuate="auto|user"> |
§ 7.2 |
|
Collegamento esteso: <xlink:extended role="significato" title=" titolo"showdefault="replace|new|parsed" actuatedefault="auto|user"> <xlink:locator href="localizzatore_1" id="identificatore_1" role="significato1" title="titolo_1"/> [Eventuali altri localizzatori] <xlink:arc from=" identificatore_i"to="identificatore_j" show="replace|new|parsed" actuate="auto|user"/> [Eventuali altri archi] </xlink:extended> |
§ 7.3 |
|
Introduzione di un collegamento in un elemento qualsiasi: <ELEMENTO xlink:type="simple|extended|locator|arc" [Altri attributi relativi al collegamento, preceduti dal prefisso "xlink"] > |
§§ 7.1 e 7.2 |
|
Gruppo di collegamenti estesi: <xlink:group steps="livelli_da_elaborare"> <xlink:document href="localizzatore_1"/> […] </xlink:group> |
§ 7.4 |
Appendice B: Riferimenti bibliografici
Bibliografia
| [1] |
Charles F. Goldfarb, Paul Prescod. XML. McGraw-Hill, 1999. |
|
[3] |
Paolo Atzeni, Stefano Ceri, Stefano Paraboschi, Riccardo Torlone. Basi di dati. Concetti, linguaggi e architetture. McGraw-Hill, 1996. |
|
[5] |
Ed Tittel, Norbert Mikula, Ramesh Chandak. XML For Dummies. Apogeo, 1998. |
|
[18] |
Emily A. Vander Veer. JavaScript For Dummies Espresso. Apogeo, 1997. |
|
[19] |
William J. Pardi. XML in Action. Mondadori Informatica, 1999. |
Bibliografia "on-line"
| [2] |
Dan Suciu. Semistructured data and XML. 1998. http://www.research.att.com/~suciu/strudel/external/files/_F593433959.ps |
|
[4] |
Charles F. Goldfarb. A Brief History of the Development of SGML. SGML Users’Group, 1990. |
|
[6] |
Tim Bray, Jean Paoli, C. M. Sperberg-McQueen. Extensible Markup Language (XML) 1.0 - W3C Recommendation 10-February-1998. W3C, 1998. |
|
[7] |
Paolo De Lazzaro. XML eXtensible Markup Language. HTML point, 1998. |
|
[8] |
Andrea Conti, Andrea Corsini, Massimo Vaglini. SGML. Università degli Studi di Firenze, 1996. |
|
[9] |
Dave Raggett. XHTML:The Extensible Hypertext Markup Language. Da: March 1999 W3LA event in Stockholm. |
|
[10] |
Mark Johnson. XML for the absolute beginner. Web Publishing, 1999. http://www.javaworld.com/javaworld/jw-04-1999/jw-04-xml_p.html |
|
[11] |
Marco Calvo, Fabio Ciotti, Gino Roncaglia, Marco Zela. Internet ’98. Laterza, 1998. http://www.laterza.it/internet/internet98/online/00_indic.htm |
|
[12] |
Todd Freter. XML: Mastering Information on the Web. Sun Microsystem, 1998. |
|
[13] |
Chris Lilley, Vincent Quint. Extensible Stylesheet Language (XSL). W3C, 1999. |
|
[14] |
XML for Managers. ArborText, 1998. http://www.arbortext.com/Think_Tank/XML_Resources/XML_for_Managers/xml_for_managers.html |
|
[15] |
Jon Bosak. XML, Java, and the Future of the Web. 1997. |
|
[16] |
Kevin Werbach. La guida Bare Bones di HTML. 1999. http://werbach.com/barebones/it/it_barebone.html |
|
[17] |
Pierdomenico Corongiu. eXtensible Markup Language. 1999. |
|
[20] |
James Clark. Associating Style Sheets with XML documents. W3C, 1999. |
|
[21] |
Steven Pemberton, Murray Altheim, Daniel Austin et al. XHTML™ 1.0: The Extensible HyperText Markup Language. W3C, 1999. |
|
[22] |
Irène Vatton. Amaya New Features History. W3C, 1999. |
|
[23] |
XML Developer's Guide. Microsoft Corporation, 1999. http://msdn.microsoft.com/xml/xmlguide/default.asp |
|
[24] |
Charles Heinemann. How Much Is That in Balboas? Accessing the Typed Value of XML Elements via Visual Basic. Microsoft Corporation, 1999. http://msdn.microsoft.com/xml/articles/xml061598.asp |
|
[25] |
XSL Developer's Guide. Microsoft Corporation, 1999. http://msdn.microsoft.com/xml/XSLGuide/default.asp |
|
[26] |
James Clark. XSL Transformations (XSLT) Specification. W3C, 1999. |
|
[27] |
Massimiliano Valente. Fogli di stile. HTML Point, 1999. http://www.html.it/css/index.html |
|
[28] |
Stephen Deach. Extensible Stylesheet Language (XSL) Specification. W3C, 1999. http://www.w3.org/TR/1999/WD-xsl-19990421 |
|
[29] |
Norman Walsh. The XSL Debate: One Expert's View. 1999. http://www.arbortext.com/Think_Tank/Norm_s_Corner/Issue_One/issue_one.html |
|
[30] |
Michael Leventhal. XSL Considered Harmful. 1999. http://xml.com/xml/pub/1999/05/xsl/xslconsidered.html |
|
[31] |
Robin Cover. XSL/XSLT Software Support. Oasis, 1999. http://www.oasis-open.org/cover/xslSoftware.html |
|
[32] |
XML Data Types Reference . Microsoft Corporation, 1999. http://msdn.microsoft.com/xml/reference/schema/datatypes.asp |
|
[33] |
XML Schema Reference . Microsoft Corporation, 1999. http://msdn.microsoft.com/xml/reference/schema/start.asp |
|
[34] |
Dan Connolly. Extensible Markup Language (XMLTM). W3C, 1999. http://www.w3.org/XML/ |
|
[35] |
James Clark. XML Namespaces.1999. http://www.jclark.com/xml/xmlns.htm |
|
[36] |
XSL Reference . Microsoft Corporation, 1999. http://msdn.microsoft.com/xml/reference/xsl/start.asp |
|
[37] |
XML DOM Reference . Microsoft Corporation, 1999. http://msdn.microsoft.com/xml/reference/xmldom/start.asp |
|
[38] |
James Clark, Steve DeRose. XML Path Language (XPath) Version 1.0. W3C, 1999. http://www.w3.org/1999/08/WD-xpath-19990813 |
|
[39] |
Steve DeRose, David Orchard, Ben Trafford. XML Linking Language (XLink). W3C, 1999. http://www.w3.org/1999/07/WD-xlink-19990726 |
|
[40] |
Justin Ludwig. An Investigation of XML with Emphasis on Extensible Linking Language (XLL). College of Wooster, 1999. http://pages.wooster.edu/ludwigj/xml/thesis.html |
|
[41] |
Gabe Beged-Dov. XArc (a.k.a. XLink--++).1998. http://www.jfinity.com/xarc/spec-981221 |
|
[42] |
Robin Cover. XML Linking and Addressing Languages (XPath, XPointer, XLink). Oasis, 1999. |
|
[43] |
Steve DeRose, Ron Daniel Jr. XML Pointer Language (XPointer). W3C, 1999. http://www.w3.org/1999/07/WD-xptr-19990709 |
|
[44] |
Chris Lilley. W3C Scalable Vector Graphics (SVG). W3C, 1999. http://www.w3.org/Graphics/SVG/ |
|
[45] |
Patrick Ion, Robert Miner. Mathematical Markup Language (MathML™) 1.01 Specification. W3C, 1999. http://www.w3.org/1999/07/REC-MathML-19990707/ |
|
[46] |
Vincent Quint, Irène Vatton. Using Amaya. W3C, 1999. http://www.w3.org/Amaya/User/Manual.html |
|
[47] |
Lauren Wood, Arnaud Le Hors, Vidur Apparao et al. Document Object Model (DOM) Level 2 Specification. W3C, 1999. http://www.w3.org/TR/WD-DOM-Level-2/ |