Il World Wide Web nacque alla fine degli anni ’80 da un’idea di Tim Barners Lee, un ricercatore del CERN di Ginevra. Il suo scopo era quello di sviluppare un sistema ipertestuale di pubblicazione e reperimento di informazioni distribuito sulla rete geografica Internet (già preesistente), in grado di tenere in contatto la comunità mondiale dei fisici. Il presupposto di Barners Lee e dei suoi collaboratori era che quelle informazioni fossero testo con in più alcune immagini e collegamenti ipertestuali.
In dieci anni, la tecnologia Web ha fatto registrare una crescita ed un’accettazione oltre ogni aspettativa, diventando un nuovo modello di diffusione e acquisizione di informazioni di qualsiasi genere. Per molte aziende ed enti pubblici, il Web è ormai diventato uno strumento di lavoro, che consente di offrire numerosi servizi, tra cui:
· pubblicità e commercio elettronico;
· pubblicazione di notizie in tempo reale;
· distribuzione di archivi, bibliografie, materiale didattico;
· possibilità di effettuare investimenti finanziari “on-line” (su cui è basata la cosiddetta “new economy”);
· ecc.
Niente di tutto ciò è possibile senza interfacciare le basi di dati dei vari fornitori di informazioni con il Web. Come vedremo in dettaglio nel capitolo 1, quest’operazione risulta problematica, specialmente a causa della differenza tra i dati fortemente strutturati gestiti dai database, e quelli “semistrutturati” presenti nel Web.
Due recenti novità possono contribuire ad un miglioramento della situazione in questo campo:
1) Lo sviluppo di nuovi software in grado di creare e gestire siti Web in maniera semplice, sfruttando la materializzazione delle informazioni di una base di dati per costruire ed aggiornare automaticamente le pagine del sito.
2) L’introduzione di XML (eXtensible Markup Language), un nuovo linguaggio in grado di rappresentare le informazioni strutturate delle basi di dati all’interno delle pagine Web.
Questa tesi sperimentale ha come obiettivo principale la realizzazione di un software che generi documenti XML a partire dalle informazioni contenute in una base di dati relazionale. Il programma si chiama “CreaXML” ed è un’applicazione scritta in Java e pensata per essere eseguita su un computer che abbia funzioni di server Web.
Vediamo, in breve, il funzionamento di “CreaXML” (per i dettagli si rimanda al capitolo 4):
1) L’utente interroga il database per mezzo di un’interfaccia grafica.
2) Alla pressione di un pulsante sull’interfaccia, l’applicazione genera automaticamente i documenti XML contenenti i risultati delle interrogazioni (uno per ogni query). Sarà, poi, compito del webmaster rendere disponibili sul Web i file prodotti.
3) Le pagine XML prodotte da “CreaXML” hanno caratteristiche dinamiche: utilizzando il solo browser, è possibile, oltre che visualizzarle, eseguire ordinamenti e ricerche sui dati contenuti in esse, senza bisogno di riconnettersi al server.
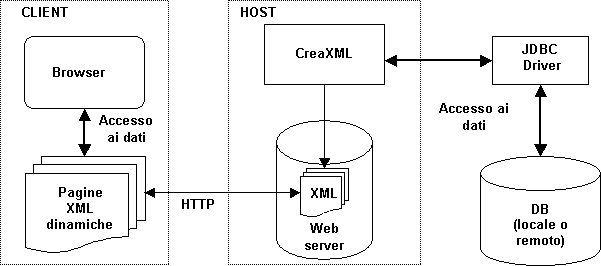
Questo schema chiarisce la collocazione di “CreaXML” all’interno della “classica” architettura client/server per l’accesso al Web:
Figura 0: Collocazione di “CreaXML”
La base di dati può trovarsi anche su un computer diverso rispetto all’host che ospita il Web server e “CreaXML”. Questo è possibile grazie alle caratteristiche dei driver JDBC (Java Data Base Connectivity), che analizzeremo nel § 1.6.3.
Per realizzare il progetto “CreaXML”, sono stati necessari la conoscenza e l’utilizzo di diverse tecnologie:
·
Java:
è un linguaggio di programmazione ad oggetti sviluppato dalla Sun Microsystem.
La sua caratteristica fondamentale è l’indipendenza dalla piattaforma. È
altrettanto importante, dal nostro punto di vista, la facilità con cui esso può
accedere ad una base di dati. Il codice di
“CreaXML” è scritto completamente in Java 2.0.
· XML: è un linguaggio di markup* ideato dal W3 Consortium (W3C) allo scopo di rappresentare i dati strutturati sul Web. “CreaXML” trasforma i risultati delle interrogazioni eseguite dall’utente sulla base di dati in documenti XML.
· XSL (eXtensible Stylesheet Language): è un’applicazione di XML per la stesura dei fogli di stile, file che vanno abbinati ai documenti XML per definirne la visualizzazione. “CreaXML” si occupa anche di generare un opportuno foglio di stile XSL per ogni documento XML prodotto.
·
HTML (HyperText
Markup Language): è il linguaggio di markup con il quale sono scritte le
pagine Web, inventato nel 1989 da Barners Lee e giunto, ormai, alla versione
4.01. XSL prevede la possibilità di trasformare il documento XML in una pagina
HTML per favorirne la visualizzazione da parte dei browser Web.
Quest’opportunità è sfruttata dai fogli di stile di
“CreaXML”
· Javascript: è un linguaggio di programmazione (molto più semplice e meno potente di Java) sviluppato dalla Netscape per estendere le capacità delle pagine Web. Ciò avviene per mezzo di “script” inseriti all’interno del codice HTML, che vengono interpretati ed eseguiti direttamente dal browser. Diversi script in questo linguaggio sono implementati all’interno dei fogli di stile XSL di “CreaXML”.
· DOM (Document Object Model): è il modello ad oggetti ideato dal W3C per i documenti HTML ed XML. Esso definisce gli oggetti e gli eventi utilizzati da Javascript per modificare dinamicamente le pagine Web.
· CSS (Cascading Style Sheets): è un linguaggio per la scrittura di fogli di stile progettato dal W3C per HTML. Esso è applicabile anche ai documenti XML, pur risultando meno potente di XSL. “CreaXML” è in grado di visualizzare le informazioni estratte dalla base di dati anche con fogli di stile di questo tipo.
· SQL (Structured Query Language): è il linguaggio standard per l’interrogazione delle basi di dati relazionali. È utilizzato in “CreaXML” per l’inserimento delle query (interrogazioni) i cui risultati saranno, in seguito, materializzati sottoforma di file XML.
La scrittura dell’applicazione “CreaXML” non esaurisce il lavoro di questa tesi. Essa si propone, inoltre, di affrontare in maniera coerente, sebbene senza pretese di completezza, le problematiche introdotte dalla necessità, sempre più attuale, di far interagire le “tradizionali” basi di dati e il World Wide Web. In particolare, il contenuto dalla tesi è organizzato in questo modo:
Capitolo 1: Sistemi informativi su Web. Sono descritti i problemi tecnologici che complicano la realizzazione di sistemi informativi su Web. Vengono, poi, presentate le soluzioni attualmente più diffuse per l’accesso alle basi di dati attraverso il Web e per la realizzazione automatica di siti Web a partire dai dati.
Capitolo 2: XML. È presentato il linguaggio XML con le sue principali applicazioni. Sono evidenziati sia i vantaggi che esso può apportare al Web, sia i motivi che ne stanno ritardando la diffusione.
Capitolo 3: Il progetto Araneus. Araneus è un software sperimentale sviluppato dall’Università di Roma Tre e dall’Università della Calabria, che si propone, tra l’altro, di generare siti Web a partire dalle informazioni contenute in una base di dati relazionale. Il capitolo descrive questo progetto, i suoi pregi e i suoi limiti nella generazione di pagine XML.
Capitolo 4: L’applicazione “CreaXML”. Sono spiegate le caratteristiche e le istruzioni d’uso del software “CreaXML”.
Capitolo 5: Tecnologie utilizzate per “CreaXML”. È spiegato in dettaglio il funzionamento di “CreaXML”: le classi Java adoperate, le proprietà dei documenti prodotti, ecc.
Capitolo 6: Sperimentazione di “CreaXML”. Vengono descritti i vari esperimenti effettuati per testare l’applicazione “CreaXML”, utilizzando vari driver per interfacciarla con diversi sistemi di gestione di basi di dati.
Capitolo 7: Conclusioni. È valutato l’impiego di “CreaXML” per semplificare la gestione di un sito Web centrato sui dati. Sono, inoltre esposti i limiti del programma, con le proposte per eventuali miglioramenti futuri.
Appendici. In questa sezione si trovano i listati completi di “CreaXML” e dei suoi modelli di foglio di stile e le specifiche di riferimento dei diversi linguaggi introdotti nel corso della tesi. Non manca, ovviamente, la bibliografia, in gran parte costituita da articoli e documenti presenti sul Web.
Desidero ringraziare innanzitutto il mio relatore, il professor Maurizio Panti, per la sua grande disponibilità e per la libertà lasciatami nella scelta degli argomenti della tesi e nello sviluppo del programma. Un particolare ringraziamento va anche alla dottoressa Emanuela Merelli, che mi ha messo a disposizione il libro “Data on the Web”, introvabile in Italia. Infine, vorrei ringraziare alcuni miei amici: Alessandro e Nunzia, che mi hanno aiutato a revisionare e correggere la tesi ed Ezio, che mi ha fornito utili suggerimenti riguardanti la programmazione in Java.
* I linguaggi di markup, il più famoso dei quali è senz’altro HTML, producono documenti in formato testuale. In essi coesistono le informazioni, scritte sottoforma di testo semplice, e il markup, costituito dai tag (o marcatori), particolari stringhe di caratteri aggiunte al testo per dare un’interpretazione semantica al documento e alle sue varie parti.