1 SISTEMI INFORMATIVI SU WEB
1.1
Evoluzione del World Wide Web
Il World Wide Web può essere definito come un ipertesto multimediale distribuito [1]. Soffermiamoci sul significato di queste tre parole:
·
Il termine ipertesto fu coniato da Theodor Holm Nelson, in un saggio pubblicato
nel 1965 [2].
Esso rappresenta un insieme di documenti, interconnessi fra loro con una
struttura non sequenziale, al fine di permettere diversi percorsi di
consultazione, a seconda delle esigenze.
· L’ipertesto costituito dal Web contiene non solo documenti testuali, ma anche immagini, suoni, filmati, ecc. Pertanto si tratta di un ipertesto multimediale.
· Il Web è ospitato da Internet, una federazione di reti di computer estesa in tutto il mondo. Dunque è un ipertesto multimediale distribuito.
Il Web fornisce un modello semplice ed universale per lo scambio di informazioni, che si basa sulla decomposizione di queste in elementi che possano essere trasmessi sulla rete Internet [3]. Ciascuno di questi elementi è un file, creato da un utente del Web, al quale viene assegnato un nome univoco, detto URL (Uniform Resource Locator). Tutti gli altri utenti del Web, indipendentemente dal sistema utilizzato, possono ottenere il file dalla rete semplicemente richiamandone l’URL.
Lo straordinario successo ottenuto dal Web è dovuto principalmente ad HTML (HyperText Markup Language), il linguaggio adottato per la composizione dei documenti ipertestuali [4]. La sua semplicità ha consentito ai programmatori in tutto il mondo di realizzare velocemente sistemi e strumenti in grado di operare sul Web. Non va trascurata, inoltre, l’introduzione del protocollo HTTP (HyperText Transfer Protocol), anch’esso molto semplice, divenuto ben presto lo standard per lo scambio di informazioni sul Web.
La vasta e rapida diffusione di Internet ha portato negli ultimi anni un notevole incremento della complessità dei dati distribuiti via Web [5]. Questo è ormai diventato una piattaforma globale per sistemi informativi di ogni genere, aventi in comune il solo fatto di essere accessibili per mezzo di un browser, un software client per la “navigazione” sul Web. Tali sistemi vengono spesso indicati in letteratura con la sigla WIS (Web Information Systems).
Un grande impulso allo sviluppo dei WIS è stato dato principalmente da due fattori [5]:
1) L’integrazione sul Web dei “tradizionali” DBMS (Data Base Management Systems): sempre più frequentemente sono questi software a gestire, almeno in parte, i dati contenuti nei siti Web.
2) L’utilizzo di “browser intelligenti”, che consentono l’esecuzione locale di “codice mobile”, cioè di programmi trasferiti tramite Internet dal server al client, in grado di estendere le capacità dei browser e di migliorare l’accesso ai dati presenti nei siti [5]. Le principali tecnologie utilizzate a questo proposito sono [6]:
· gli Applet Java;
· i controlli ActiveX della Microsoft;
· i plug-in di Netscape.
1.2 Le informazioni nel Web e nelle basi di dati
1.2.1 Tipi di dati gestiti dal Web
Teoricamente, il Web può essere considerato come la più grande base di dati mai creata. In concreto, questo approccio risulta impraticabile, poiché non esiste una coerenza nel modello delle informazioni in esso contenute. I browser Web e i client di posta elettronica possono accedere a tutti gli oggetti descritti dallo standard MIME (Multipurpose Internet Mail Extension), il quale prevede sette tipi fondamentali di dati [7]:
text, image, audio, video, application, multipart, message.
Per ciascuno di questi il protocollo prevede dei sottotipi, come ad esempio: “text/html”, “image/gif”, “application/pdf”, il cui numero è, però, grande ed in continua crescita [8]. Questa varietà di tipi impedisce un’effettiva utilizzabilità delle informazioni. Basti pensare, ad esempio, ai motori di ricerca sul Web che, nella maggior parte dei casi, limitano il loro raggio d’azione ad una semplice ricerca testuale sui soli file HTML.
1.2.2 Tipi di dati gestiti dai DBMS
I DBMS tradizionali, viceversa, prevedono un insieme ristretto di tipi di dati: numeri interi e decimali, stringhe di caratteri e di bit, date ed orari [1]. Questi tipi, chiamati atomici, possono essere combinati per definire tipi di dati più complessi, come [6]:
· i tipi astratti, nelle basi di dati relazionali;
· le classi, nelle basi di dati orientate agli oggetti.
Le informazioni contenute nei DBMS sono altamente strutturate e descritte formalmente dal modello ER (Entity-Relationship) a livello logico e dagli schemi relazionali a livello applicativo.
Tale rigore teorico, unito a decenni di sviluppo tecnologico, ha generato sistemi software efficienti, capaci di gestire basi di dati anche molto estese [1]. Attualmente i DBMS sono in grado di garantire integrità, consistenza e sicurezza dei dati, nonché di facilitarne l’accessibilità, grazie ad SQL (Structured Query Language), un potente linguaggio d’interrogazione, ormai universalmente diffuso.
1.2.3 Basi di dati distribuite
Inizialmente, queste caratteristiche avanzate sono rimaste confinate ai singoli DBMS con la classica architettura client-server. Negli ultimi anni sono state estese alle basi di dati distribuite, grazie allo sviluppo di alcuni standard di accesso ai dati, come:
· il protocollo X-Open DTP (Distributed Transaction Processing), che assicura la possibilità di far interagire in una stessa transazione DBMS diversi;
· l’interfaccia ODBC (Open DataBase Connectivity), che permette l’accesso a dati remoti e la costruzione di applicazioni eterogenee.
A questo punto viene da chiedersi se sia possibile un’ulteriore miglioramento di questi standard e delle tecnologie che li realizzano, allo scopo di trasformare effettivamente il Web in un’unica base di dati distribuita. La risposta è, purtroppo, negativa, e le sue motivazioni si trovano nei limiti dei due capisaldi del Web: HTTP ed HTML.
1.2.4 Limiti del protocollo HTTP
Il protocollo HTTP non ha memoria: nel caso di operazioni complesse, il server Web non è in grado di mantenere informazioni sui passi già effettuati e sul loro esito. Si tratta chiaramente di una limitazione del protocollo, che rende impossibile la realizzazione di procedure in ambiente concorrente, come quelle necessarie per le transazioni su basi di dati.
Una soluzione semplice e molto utilizzata per questo problema è fornita dai cookie: piccoli file di testo (la dimensione massima è di 4KB) che il server può mandare al client in un opportuno campo dell’intestazione di una risposta HTTP. Vediamone un esempio:
ID=843425ee369b46ef4c50910f62e3ded5
telecomitalia.it/
0
642859008
31887777
3469567296
29309374
*
Il browser memorizza il contenuto del cookie come parte della sua configurazione, e lo invia al server che lo ha generato ad ogni nuova connessione. In questo modo il server può identificare l’utente e riconoscere le sue azioni successive nell’ambito di una stessa sessione.
1.2.5 Limiti del linguaggio HTML
I documenti HTML sono composti da semplice testo, al quale si aggiungono i tag, stringhe racchiuse all’interno di parentesi angolari che definiscono le caratteristiche del documento e delle sue parti.
Consideriamo un frammento di una pagina Web scritta in HTML:
<HR SIZE=4>
Benvenuti! Questo e' il WWW server dell'Istituto di Informatica
dell'Universita' di Ancona.
<BR>
Qui puoi trovare informazioni sull'Istituto, sul personale che ci lavora, sui corsi, sulle aree di ricerca e sulle attivita' dell'Istituto.
<TABLE>
<TBODY>
<TR><TD>
<A href="menu.html ">
<IMG align=center height=40 src="immagini/menu.gif" width=40>
</A>
Fai click su questa icona per andare al
<A href="menu.html ">Menu Principale</A><BR><BR>
</TD></TR>
Si nota che sono presenti contemporaneamente [3]:
· le informazioni “utili”: nome dell’università e dell’istituto, contenute all’interno del testo;
· l’organizzazione ipertestuale, realizzata dai tag <A>, ognuno dei quali costituisce un collegamento ad un altro file del Web;
· la presentazione grafica e la formattazione del testo, affidata ad opportuni tag, come <IMG>, <TABLE>, ecc.
HTML è particolarmente adatto allo sviluppo di documenti ipertestuali, ma risulta assolutamente carente per applicazioni più avanzate, come commercio elettronico, home banking, ricerche bibliografiche on-line, ecc [1]. Attività simili sono supportate quasi sempre da DBMS e, per migliorare la loro efficienza, occorre un linguaggio capace di descrivere le informazioni strutturate utilizzate dalle basi di dati. Tale linguaggio esiste, si chiama XML (eXtensible Markup Language), ed è stato introdotto nel 1998 dal World Wide Web Consortium come formato per lo scambio di dati strutturati su Web [3]. Non ci soffermiamo qui su XML, poiché ad esso è dedicato il prossimo capitolo.
Parallelamente all’introduzione di XML, i DBMS stanno acquisendo funzioni nuove, che consentono loro di interagire meglio con il Web. Questi progressi sono possibili grazie allo studio sui dati contenuti nel Web, definiti “semi-strutturati” e descritti dal nuovo modello formale OEM (Object Exchange Model).
1.3 Siti Web centrati sui dati
Abbandonata l’idea di vedere l’intero Web come un’unica base di dati distribuita, si potrebbe verificare l’errore contrario, considerando ciascuna sua pagina come una fonte informativa autonoma [1]. Questo è il punto di vista dei motori di ricerca, ed è chiaramente insoddisfacente, poiché le pagine Web non sono quasi mai avulse dal contenuto generale del sito che le ospita fisicamente. I siti Web possono avere dimensioni molto diverse, ma solitamente:
· sono sotto il controllo di un singolo soggetto (o di più soggetti coordinati fra loro);
· hanno una specifica finalità
e, pertanto, possono essere considerati a tutti gli effetti come sistemi informativi.
Agli inizi del Web, i siti erano piccoli insiemi di pagine scritte in HTML una alla volta, utilizzando semplici editor visuali compresi nei browser, o convertendo automaticamente documenti elettronici preesistenti. Da allora, il concetto di sito Web si è evoluto in molteplici direzioni diverse [9]. È comunque possibile, oltre che utile, una classificazione dei siti a seconda della loro complessità in termini di dati ed applicazioni.
1) Siti di “presenza sul Web”: sono composti da poche pagine, utilizzate prevalentemente a scopo pubblicitario. In essi l’aspetto grafico accattivante ha un’importanza maggiore rispetto all’effettivo contenuto informativo. Sono creati e gestiti “manualmente” o con semplici strumenti di sviluppo, come, ad esempio Microsoft Front Page [10].
2) Siti orientati ad un servizio particolare, come i motori di ricerca o i fornitori di caselle e-mail gratuite [9]. Gestiscono molte informazioni, ma la struttura dei dati e dell’ipertesto è relativamente semplice, poiché comprende una sola classe di oggetti. La loro complessità è tutta nello sviluppo delle applicazioni che garantiscono il servizio.
3) Siti “catalogo”: pubblicano molti dati ed hanno una struttura ipertestuale complessa, ma offrono una scarsa interattività. Esempi tipici di questa categoria sono i siti universitari, contenenti informazioni sui corsi, sulle attività di ricerca, sul personale, ecc. Senza opportuni strumenti di sviluppo, la manutenzione contemporanea dei dati e della loro rappresentazione ipertestuale può risultare problematica [1].
4) WIS avanzati: gestiscono dati complessi ed offrono sofisticati servizi interattivi [9]. Rientrano in tale ambito i siti dedicati al commercio elettronico e quelli in grado di supportare forme di lavoro cooperativo fra le varie sedi di un’azienda o, addirittura, di telelavoro.
Il seguente grafico chiarisce meglio la classificazione appena introdotta:
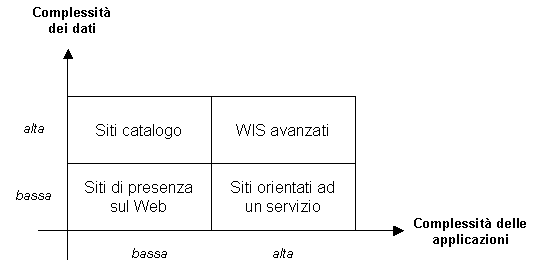
Figura 1.1: classificazione dei siti Web
I siti che traggono vantaggio dalla memorizzazione dei dati in un DB sono quelli ad alta complessità dei dati (siti “catalogo” e WIS avanzati), che possiamo definire anche siti “centrati sui dati” [1]. Le possibili interazioni con un DBMS sono di tre tipi:
-
Consultazione di un DB remoto per mezzo di un’interfaccia sul Web.

- Comunicazione bidirezionale fra Web e DBMS: la base di dati può essere interrogata ed aggiornata tramite Web. Le transazioni necessarie si spostano attraverso Internet.

-
Realizzazione e manutenzione di siti Web generati automaticamente a partire dai dati di un DB.

Occupiamoci ora delle tecniche e degli strumenti attualmente disponibili per accedere ad un DB attraverso il Web. Nel § 1.8 tratteremo la generazione di siti Web a partire dai dati gestiti da un DBMS.
1.4 Accesso a basi di dati tramite programmi CGI
La soluzione più semplice, e più adottata nei siti Web, per interfacciare il browser con una base di dati è quella che utilizza i form (o moduli) di HTML per impartire le direttive di accesso e lo schema HTTP/CGI (Common Gateway Interface) per la comunicazione client-server [5]. Questa soluzione comprende tre sistemi che interagiscono fra loro: il browser, il Web server e il DBMS.
Quando il browser si collega all’URL di accesso alla base di dati, esso riceve dal Web server un documento HTML contenente un form: una schermata simile ad un modulo prestampato con la possibilità di inserire dati solo in alcuni campi, come questa [1]:
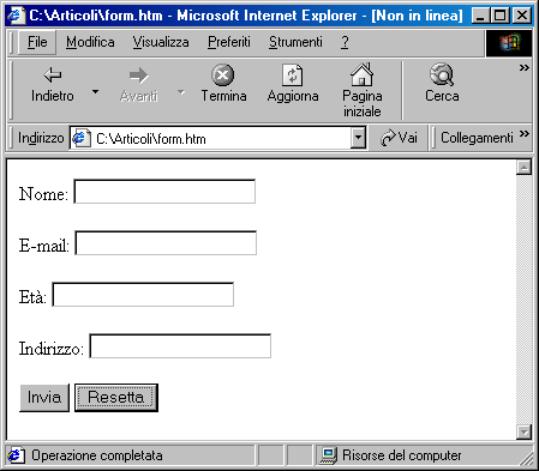
Figura 1.5: Visualizzazione di un form HTML
Il codice HTML che genera il semplice form qui sopra è il seguente [11]:
<form action="http://vostroserver.it/cgi-bin/post.cgi" method="POST"> <p>Nome: <input type="text" name="nome"></p> <p>E-mail: <input type="text" name="email"></p> <p>Età: <input type="text" name="età"></p> <p>Indirizzo: <input type="text" name="indirizzo"></p> <p><input type="submit" value="Invia"> <input type="reset" value="Resetta"></p> </form>
La definizione del modulo è costituita dal tag <form>, che contiene due attributi [5]:
1) action, che specifica il nome dello script CGI da attivare sul server;
2) method, che determina il metodo tramite il quale comunicheranno il Web server e lo script. Esso può assumere due valori [11]:
- GET: con la sola pressione del tasto “Invio” le informazioni vengono inviate al CGI che procederà ad interpretarle. Solitamente gli argomenti di GET sono passati al CGI come:
http://vostroserver.it/cgi-bin/script.cgi?argomenti
- POST: è un metodo più affidabile di GET poiché non utilizza il carattere “?” per passare le informazioni, ma le manda allo script nella forma di un flusso di input, chiamato STDIN (standard input) e costituito dai campi del form.
In entrambi i casi, i parametri forniti dalla pagina HTML sono trasferiti via HTTP al Web server che attiva lo script CGI [5]. Questo si occupa di:
a) leggere e decodificare i parametri;
b) aprire una connessione con la base di dati, usando librerie native del DBMS, specifiche per il sistema operativo del server;
c) eseguire la query;
d) inviare il risultato al Web server, che lo spedisce al browser sottoforma di un nuovo documento HTML.
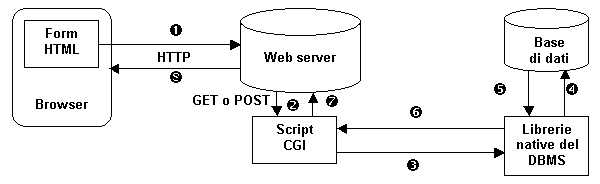
Figura 1.6: Utilizzo di HTML con schema HTTP/CGI. I numeri
indicano la sequenza delle operazioni.
Vediamo ora quali sono i limiti di questo metodo:
1) L’interfaccia utente realizzata da un form di HTML è, per sua natura, statica e poco efficace. Infatti, non è possibile controllare la validità dei dati inseriti dall’utente, o fornire a questi strumenti d’ausilio dipendenti dal contesto in cui opera. Questo problema potrebbe essere risolto mediante continue interazioni fra browser e Web server, ma una soluzione di questo tipo non è praticabile, a causa dei tempi di risposta.
2) Il programma CGI deve essere scritto in un linguaggio che dipende dal sistema operativo del server. Vediamo, per esempio, un semplice script in Perl, linguaggio nato per Unix e successivamente introdotto anche su altre piattaforme [12]:
#!/usr/bin/perl
print
"Content-type:text/html\n\n";
read(STDIN,
$buffer, $ENV{'CONTENT_LENGTH'});
@coppie = split(/&/, $buffer);
foreach $pair (@coppie) {
($nome, $valore) = split(/=/,
$coppia);
$valore =~ tr/+/ /;
$valore =~
s/%([a-fA-F0-9][a-fA-F0-9])/pack("C", hex($1))/eg;
$HASH{$nome} = $valore;
}
print
"<html><head><title>Form
Output</title></head><body>";
print
"<h2>Risultati del form</h2>\n";
foreach
$key (keys(%HASH)) {
print "$key =
$HASH{$key}<br>";
}
print
"</body></html>";
Questo script si limita a produrre una pagina HTML contenente i risultati del form presentato poco fa. In generale, però, i programmi CGI devono usare librerie esterne scritte in un linguaggio diverso per poter interagire con i DBMS [5]. La portabilità di questo sistema di accesso ai dati risulta, pertanto, modesta.
3) Lo svolgimento di azioni cooperative fra client e server è impossibile, a causa della mancanza di memoria del protocollo HTTP (vedi § 1.2.4). Per ogni richiesta proveniente dal browser, occorre l’attivazione e l’esecuzione di un nuovo modulo CGI. Questa caratteristica può sovraccaricare il Web server, diventando così la fonte principale di degrado delle prestazioni o di blocchi del server stesso.
1.5 Soluzioni proprietarie dei produttori di software
Le tecniche alternative all’uso del protocollo CGI possono essere divise in due categorie [1]:
· soluzioni basate sul server, in cui il client è un browser standard ed è il server che interagisce in modo opportuno con la base di dati;
· soluzioni basate sul client, che tendono ad estendere le funzionalità del browser, assegnando ad esso alcune delle mansioni del Web server.
1.5.1 Soluzioni basate sul server
Per ovviare ai problemi di prestazioni dello schema HTTP/CGI sono stati introdotti i server API (Application Programming Interface), dotati di librerie che permettono di accedere alla base di dati tramite ODBC [5]. Uno strumento di questo tipo è Internet Server API, prodotto dalla Microsoft. La Oracle si è spinta oltre, distribuendo Oracle Application Server [13]. Questo Web server può accedere direttamente ai dati, ma solo se sono stati creati da un software Oracle.
Il beneficio principale di quest’approccio è la riduzione delle operazioni di accesso ai dati, con un conseguente miglioramento delle prestazioni [1]. Il prezzo da pagare è, però, la mancanza di standardizzazione: le API offerte dai vari server, pur simili fra loro, non sono compatibili e, pertanto, le applicazioni non sono facilmente portabili su sistemi diversi.
Altri produttori di software, per conciliare le esigenze di portabilità e standardizzazione con il superamento dei limiti delle CGI, hanno proposto una soluzione intermedia, costituita dalle CGI leggere. Questa tecnica consiste nell’usare programmi CGI piccolissimi, che hanno solo due scopi: ricevere la richiesta del Web server e richiedere la connessione con un opportuno processo sempre attivo, chiamato “demone”, che si interfaccia con il DBMS. In questo modo il Web server deve occuparsi unicamente di attivare e terminare le CGI leggere, operazioni che difficilmente causeranno problemi di prestazioni.
1.5.2 Soluzioni basate sul client
È possibile evitare la pesantezza del protocollo CGI, togliendo il compito di interagire con la base di dati al Web server, ed assegnandolo ad un opportuno client:
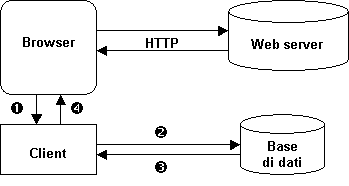
Figura 1.7: Soluzioni basate sul client
Per la realizzazione del client esistono varie possibilità:
1) Estensioni (o plug-in) del browser: si tratta di moduli software, scritti in Java, Active-X o altri linguaggi, utilizzati per accedere ad una base di dati remota. Talvolta la loro distribuzione e il loro aggiornamento risultano problematici.
2) Script incorporati nel codice HTML o, addirittura, estensioni di questo linguaggio con l’introduzione di tag non standard [5]. Esempi di questo tipo sono le ASP (Active Server Pages) di Microsoft o le applicazioni Cold Fusion, prodotte dalla Allaire Corporation [14]. Vediamo un documento Cold Fusion che esegue un’interrogazione su una base di dati:
<cfquery name="lista" datasourec="cf 3.0 examples"> select * from courses </cfquery> <html> <head> <title>Lista dei corsi</title> </head> <body> <h2>Lista dei Corsi</h2> <hr> <cfoutput query="lista"> <b>(#number#)</b> #description#<br> </cfoutput> </body> </html>
3) Viewer esterni: in alternativa alle estensioni, il browser può attivare dei software indipendenti da esso, come interpreti SQL o applicazioni locali per l’accesso a basi di dati remote [1]. In questo caso l’utente interagisce solo con questi programmi, realizzando il tradizionale schema client-server e il browser viene di fatto abbandonato.
4) Browser proprietari: alcuni produttori di DBMS hanno valutato la possibilità di realizzare browser specializzati nell’accesso alle basi di dati. L’iniziativa non ha avuto successo, a causa dell’enorme (e gratuita) diffusione dei browser general purpose, che ha ormai abituato gli utenti a questo tipo di prodotti.
Il limite principale delle soluzioni proprietarie sul Web è il non rispetto dell’indipendenza del software dalla piattaforma di esecuzione [5]. Esse, infatti, sono vincolate al Web server e al suo sistema operativo e, talvolta, il loro funzionamento può dipendere anche dal browser o dal sistema operativo del client.
1.6 Soluzioni fondate su Java
Una tecnica molto usata per la distribuzione di applicazioni su Internet è quella del “codice mobile”: essa permette di scrivere programmi che possono essere trasmessi dalla rete ed eseguiti su piattaforme hardware e sistemi operativi eterogenei [15]. Per realizzarli sono stati ideati vari linguaggi di programmazione, tra i quali citiamo Omniware, Safe TCL, Python e, soprattutto, Java.
1.6.1 Presentazione di Java
Java è un linguaggio di programmazione sviluppato dalla Sun Microsystems. La sua prima versione risale al 1996, seguita nel 1999 da Java 2 [16]. È un linguaggio orientato agli oggetti e multithreaded1; ma la sua caratteristica fondamentale è l’indipendenza dall’architettura: i codici sorgente dei programmi Java sono uguali per tutte le piattaforme in grado di supportare il linguaggio. Questi, una volta compilati, sono trasformati in file oggetto chiamati bytecode e interpretati dalla JVM (macchina virtuale Java), disponibile per la maggior parte degli attuali sistemi operativi [5].
Inoltre Java possiede un’estesa libreria di routine per gestire i protocolli TCP/IP (Transfer Control Protocol/Internet Protocol), quali HTTP e FTP (File Transfer Protocol) [16]. Le applicazioni scritte in Java possono utilizzare oggetti reperiti da Internet tramite il loro URL con la stessa facilità con cui accedono ad un file system locale.
La causa principale del successo di Java è la sua integrazione con i browser [5]. Java, infatti, può essere utilizzato sia per scrivere applicazioni complete, sia programmi particolari, chiamati applet, trasferiti via rete sul computer dove risiede il browser ed eseguiti localmente all’interno di una pagina Web scritta in HTML.
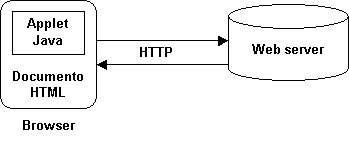
Figura 1.8: Applet Java all’interno di un documento HTML
Per la loro natura di codice mobile, le funzionalità degli applet sono sottoposte a notevoli vincoli di sicurezza. Essi non possono:
· attivare un programma locale;
· leggere o scrivere file locali;
· comunicare con host diversi dal server dal quale sono stati trasferiti.
La versione 2 di Java prevede il superamento di questi limiti per gli applet certificati da un’oppor-tuna “firma digitale”, che ne attesti la provenienza sicura [8]. A parte queste restrizioni, comunque, un applet è un programma Java a tutti gli effetti. Esso può contenere, ad esempio, un’interfaccia grafica amichevole per l’accesso ad una base di dati remota, routine di controllo sui dati immessi, e così via.
1.6.2 Introduzione a JDBC
Le Java Data Base Connectivity (JDBC) sono classi che consentono di interfacciare programmi Java con sistemi di gestione di basi di dati relazionali, in maniera indipendente dalle caratteristiche del DBMS usato [1]. L’obiettivo è analogo a quello del protocollo ODBC (vedi § 1.2.3), che è un insieme di API per il linguaggio C [8]. Per garantire l’autonomia dai DBMS, le classi JDBC utilizzano dei driver manager, che gestiscono la connessione fra le applicazioni Java e i driver specifici, rendendola completamente trasparente al programmatore. L’accesso ad una base di dati è effettuato tramite poche semplici istruzioni:
1) Dichiarazione del driver utilizzato:
Class.forName(“sun.jdbc.odbc.JdbcOdbcDriver”);
2) Connessione al DB, identificato da un URL nella forma jdbc:sottoprotocollo:nome:
Connection
con=DriverManager.getConnection(“jdbc:odbc:Department”);
3) Esecuzione di un’interrogazione in SQL:
Statement
stmt = con.createStatement();
ResultSet
rs = stmt.executeQuery(“SELECT * FROM courses”);
Il risultato della query è un oggetto di tipo ResultSet: una tabella di dati organizzati per righe e colonne. L’accesso a tali dati è permesso dai numerosi metodi dell’interfaccia omonima, sulla quale ci soffermeremo nel capitolo 5.
4) Chiusura della connessione:
stmt.close();
con.close();
Come è evidente, non ci sono istruzioni di impostazione del driver: questo viene configurato nell’ambiente del sistema operativo [5]. Per utilizzare un altro DBMS, andranno modificate nel codice Java solamente le stringhe che indicano il nome del driver e l’URL della base di dati.
1.6.3 I driver JDBC
JDBC, pur essendo un protocollo recente e ancora in fase di consolidamento, rappresenta già ora una soluzione molto interessante per la realizzazione di applicazioni Web in grado di accedere a basi di dati [1]. Sono stati sviluppati, infatti, numerosi driver JDBC, che possiamo classificare nei seguenti quattro tipi:
1) Ponte JDBC-ODBC. Traduce le istruzioni JDBC in chiamate alle API ODBC. Occorre che il computer client che esegue il codice Java disponga di un’installazione di ODBC con il driver specifico per il DBMS al quale si vuole accedere. Non è una soluzione elegante, ma permette agli sviluppatori Java di utilizzare i numerosi driver ODBC esistenti. La Sun creò questo driver come espediente temporaneo per la connessione ai DB, in attesa che venissero sviluppati degli opportuni driver JDBC.
2) Driver nativo. Converte il codice JDBC in richieste alle API native del particolare sistema di gestione di basi di dati. Il driver è specifico per il DBMS cui si vuole accedere. Anche questi driver devono essere installati sulle macchine client.
3) Middleware server. È un server di rete scritto in Java, che è responsabile di tradurre le chiamate provenienti dal driver manager nel formato riconosciuto dal particolare DBMS che si intende utilizzare. Sono già presenti sul mercato prodotti che realizzano queste funzioni, permettendo di interagire con i DB relazionali più diffusi.
4) Driver Java. Consente di effettuare le chiamate JDBC direttamente nel protocollo di rete del sistema di gestione di basi di dati, realizzando così un’interazione diretta tra applicazione Java e DBMS. Attualmente driver di questo tipo vengono normalmente offerti dai produttori di basi di dati relazionali.
Le prime due soluzioni non sono realmente portabili, poiché richiedono l’utilizzo di componenti nativi, cioè specifici dell’ambiente di esecuzione. Esse sono diffuse nelle architetture a più livelli, al fine di impiegare strumenti già esistenti.
Le potenzialità delle classi JDBC sono sfruttate maggiormente dai driver di tipo 3 e 4, scritti completamente in Java [5]. Con essi è possibile, infatti, stabilire una connessione mediata (tipo 3) o diretta (tipo 4) fra client e DBMS, e ciò vale anche nel caso di applicazioni che accedono a basi di dati tramite il Web.
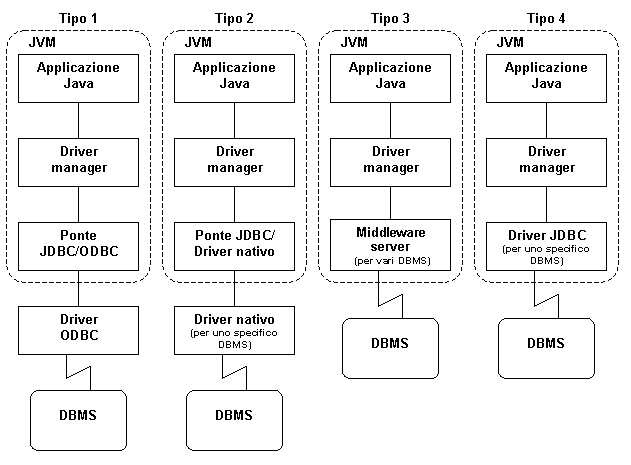
Figura 1.9: Livelli di implementazione dei quattro tipi di driver JDBC
1.6.4 Sistemi con architettura ad un livello
Il browser carica un applet Java che contiene, oltre all’interfaccia utente, il codice relativo al driver manager e alle classi JDBC. In questo modo dal browser è possibile interrogare direttamente il DB, purché esso si trovi nello stesso host da cui è stato trasferito l’applet: occorre, infatti, rispettare il vincolo di sicurezza degli applet (vedi § 1.6.1). Un sistema di questo tipo è realizzabile solo se si hanno a disposizione driver JDBC di tipo 4.
Quest’architettura presenta un
inconveniente: è necessario stabilire due connessioni HTTP: dapprima una per
trasferire l’applet, quindi una seconda per l’accesso al DB su una diversa
porta IP. Un comportamento del genere potrebbe essere ritenuto non lecito da
un “firewall”2
che, di conseguenza, impedirebbe la connessione alla base di dati.
Attualmente, un sistema di questo tipo è più adatto
ad essere utilizzato in una rete Intranet, piuttosto che sul
Web.
Figura 1.10: Sistema con architettura ad
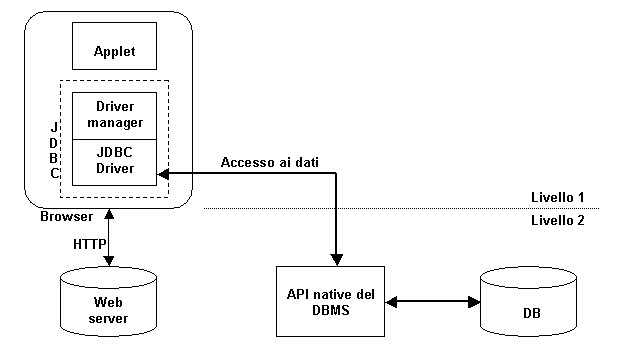
un livello Utilizzando driver JDBC di tipo 1 o 2 è
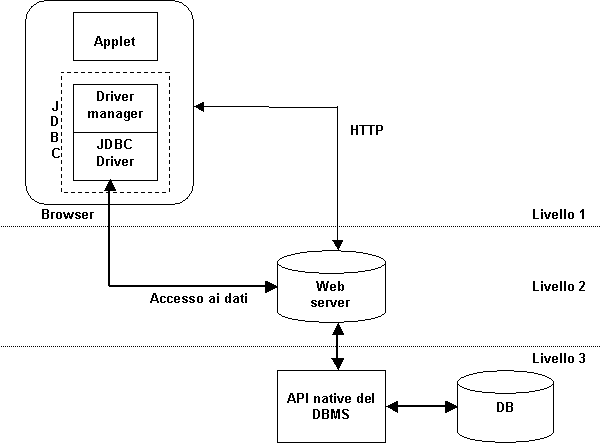
possibile realizzare sistemi con un’architettura a due livelli. ·
Al primo livello abbiamo l’applet che contiene
il codice dell’interfaccia utente, il driver manager ed il driver JDBC. ·
Al secondo livello troviamo le API native del
particolare DBMS, specifiche per il sistema operativo su cui è installato.
Per poter accedere al DB, è necessario che l’applet interagisca con le API. Sistemi di questo tipo non sono
implementabili sul Web, poiché richiedono la presenza sul client sia del
driver JDBC di tipo 1 o 2, sia, rispettivamente, del driver ODBC o delle API
native dello specifico DBMS. Ciò significa che entrambi i livelli
dell’architettura devono risiedere nel computer client: la realizzazione di
quest’architettura è, pertanto, possibile solo nell’ambito di una
Intranet. Figura
1.11: Sistema con architettura a due livelli Con un driver JDBC di tipo 3, si può
implementare un’architettura a tre livelli, come questa: Figura
1.12: Sistema
con architettura a tre livelli In questo caso i tre livelli hanno
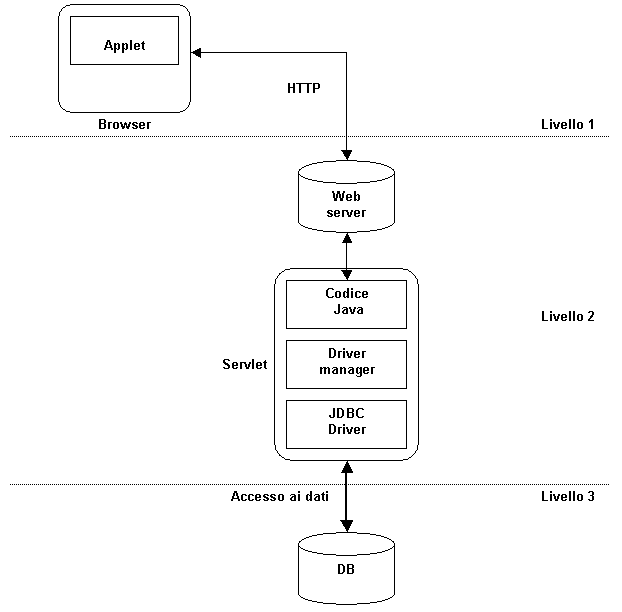
funzioni ben precise e distinte fra loro [18]: ·
Il livello presentazione è costituito dal
browser, le cui funzionalità sono ampliate da un applet Java. Esso si limita
a fornire l’interfaccia con cui l’utente interagisce con la base di dati. ·
Il livello intermedio (middleware) è formato
dal Web server e dalle sue estensioni: i servlet Java, che si connettono alla
base di dati grazie alle classi JDBC. È possibile utilizzare qualsiasi tipo
di driver JDBC . ·
Il livello “archivio dati” è composto dal
DBMS e, eventualmente, dalle sue API native, nel caso il driver JDBC usato sia
di tipo 1 o 2. Il funzionamento dell’architettura è
semplice: l’applet invia una richiesta di accesso ai dati al Web server, il
quale localizza i servlet (che eventualmente possono trovarsi in host diversi
e, pertanto, vanno trasferiti via rete) e lo attiva passandogli i parametri
[5]. I servlet interagiscono con il DB e forniscono i risultati al Web server
che, infine, li restituisce al client. I vantaggi di quest’architettura sono
numerosi [18]: a)
Dal lato client si ha un ambiente unico per accedere
all’applicazione, costituito dal browser e dall’applet che fornisce
l’interfaccia utente. Non occorre installare alcun software sulla macchina
client: l’unico requisito è la presenza su questa di un browser Web
compatibile con Java. b)
L’uso del protocollo HTTP non richiede una connessione persistente
tra client e server. Si evitano, così, i problemi tipici delle applicazioni
client-server tradizionali in cui potevano sorgere limiti sul numero degli
utenti simultanei. c)
Dal lato middleware, l’impiego dei servlet Java garantisce
l’indipendenza dalla piattaforma della macchina che ospita il Web server. d)
Sia l’applet che i servlet possono risiedere sul Web server: il
software dell’applicazione risulta centralizzato, con conseguente facilità
di manutenzione. e)
Le classi e i driver JDBC permettono l’accesso alla base di dati
senza preoccuparsi del tipo di DB, della struttura dei dati e delle
caratteristiche hardware e software dell’host che ospita il DBMS. Abbiamo visto nel § 1.6.1 che, in
applicazioni client/server basate sul Web, gli applet Java consentono di
estendere dinamicamente le funzionalità della parte client, cioè del
browser. Allo stesso modo è possibile scrivere programmi Java chiamati “servlet”, che permettono di migliorare l’efficienza del lato
server dell’applicazione. I servlet e gli applet presentano molte analogie: ·
l’utilizzo dei servlet richiede che sia
installata una macchina virtuale Java nel server su cui saranno eseguiti; ·
i servlet possono essere memorizzati su host
diversi dal sito su cui si trova il Web server: saranno trasferiti su questo
solo quando il client ne richiederà l’esecuzione. A differenza degli applet, però, i
servlet non forniscono la possibilità di implementare un’interfaccia
utente: essi interagiscono solo con il server di rete. I servlet sono scritti con le classi Java
contenute nell’API Servlet, indipendenti dal protocollo di rete usato [8].
Pertanto essi possono interagire con tutti i server di rete compatibili, a
prescindere dal servizio fornito o dal sistema operativo. Molti Web server
supportano i servlet Java; elenchiamo di seguito i più importanti: ·
Java Web Server; ·
Apache 1.1.3; ·
Netscape FastTrack 2.0, Enterprise 2.0,
Enterprise 3.0; ·
Microsoft IIS (Internet Information Server) 2.0
e 3.0; ·
IBM Internet Connection Server. I principali vantaggi dell’uso dei
servlet, rispetto ai normali script CGI, sono [5]: a)
Sono scritti in Java, che è un linguaggio multi-piattaforma. È
possibile, quindi, scrivere servlet che possono essere eseguiti, localmente o
“in remoto”, da diversi Web server, indipendentemente dal sistema
operativo di installazione. b)
L’interazione tra servlet e server di rete avviene tramite i metodi
forniti dalle classi dell’API Servlet. Ciò garantisce l’indipendenza dal
server e dai protocolli di comunicazione e, quindi, la possibilità di
riutilizo. c)
I servlet, a differenza dei CGI, sono programmi “rientranti”: non
causano la creazione di un nuovo processo ad ogni richiesta del client [18].
Il servlet, infatti, è caricato una volta per tutte nella memoria della JVM
alla sua prima invocazione, e
continua a risiedervi finché non è esplicitamente scaricato da questa [5].
Tale caratteristica consente di migliorare notevolmente le prestazioni del
sito rispetto all’uso degli script CGI ed, inoltre, permette la condivisione
di informazioni fra connessioni diverse e la riduzione del numero di processi
attivi sul server. Grazie alla flessibilità dell’API
Servlet, il codice di un servlet Java è, in generale, più semplice rispetto
a quello un analogo script CGI. Vediamo, ad esempio, il listato di un servlet
che restituisce al client i valori immessi in un form HTML [8]: Questo codice è senz’altro più
comprensibile rispetto all’analogo script CGI in Perl visto nel § 1.4. Il ciclo di funzionamento dei servlet è
composto da tre fasi, identificate da altrettanti metodi dell’interfaccia javax.servlet.Servlet
[19]: 1)
init:
inizializza il servlet. Viene richiamato solo al primo caricamento. 2)
service:
è chiamato ad ogni richiesta HTTP indirizzata al servlet. È il cuore del
programma: al suo interno sono contenute tutte le operazioni necessarie a
fornire il servizio per cui il servlet è stato predisposto. 3)
destroy:
distrugge il servlet e libera tutte le risorse che erano state allocate ad
esso. Grazie ai servlet, la realizzazione di un
sistema di accesso a basi di dati via Web con architettura a tre livelli non
richiede l’installazione di un Web server specifico [5]. Si
può utilizzare un server qualsiasi, purché supporti i Java servlet
[18]. Questi ultimi possono richiamare al loro interno le classi JDBC
realizzando, così, programmi Java in grado di stabilire una comunicazione
effettiva Web server ed un DBMS [5].
Figura
1.13: Architettura a tre livelli con servlet In questo caso i tre livelli hanno
funzioni ben precise e distinte fra loro [18]: ·
Il livello presentazione è costituito dal
browser, le cui funzionalità sono ampliate da un applet Java. Esso si limita
a fornire l’interfaccia con cui l’utente interagisce con la base di dati. ·
Il livello intermedio (middleware) è formato
dal Web server e dalle sue estensioni: i servlet Java, che si connettono alla
base di dati grazie alle classi JDBC. È possibile utilizzare qualsiasi tipo
di driver JDBC . ·
Il livello “archivio dati” è composto dal
DBMS e, eventualmente, dalle sue API native, nel caso il driver JDBC usato sia
di tipo 1 o 2. Il funzionamento dell’architettura è
semplice: l’applet invia una richiesta di accesso ai dati al Web server, il
quale localizza i servlet (che eventualmente possono trovarsi in host diversi
e, pertanto, vanno trasferiti via rete) e lo attiva passandogli i parametri
[5]. I servlet interagiscono con il DB e forniscono i risultati al Web server
che, infine, li restituisce al client. I vantaggi di quest’architettura sono
numerosi [18]: a)
Dal lato client si ha un ambiente unico per accedere
all’applicazione, costituito dal browser e dall’applet che fornisce
l’interfaccia utente. Non occorre installare alcun software sulla macchina
client: l’unico requisito è la presenza su questa di un browser Web
compatibile con Java. b)
L’uso del protocollo HTTP non richiede una connessione persistente
tra client e server. Si evitano, così, i problemi tipici delle applicazioni
client-server tradizionali in cui potevano sorgere limiti sul numero degli
utenti simultanei. c)
Dal lato middleware, l’impiego dei servlet Java garantisce
l’indipendenza dalla piattaforma della macchina che ospita il Web server. d)
Sia l’applet che i servlet possono risiedere sul Web server: il
software dell’applicazione risulta centralizzato, con conseguente facilità
di manutenzione. e)
Le classi e i driver JDBC permettono l’accesso alla base di dati
senza preoccuparsi del tipo di DB, della struttura dei dati e delle
caratteristiche hardware e software dell’host che ospita il DBMS. Nei paragrafi precedenti abbiamo trattato
estesamente l’accesso a basi di dati a partire dal Web. Quest’approccio
viene detto “pull”, in quanto i
dati che compaiono sul Web devono essere di volta in volta “tirati fuori”
dalla base di dati su richiesta dell’utente [1]. Occupiamoci ora del
problema inverso: se i dati non cambiano in tempo reale, si può pensare di
generare periodicamente l’intero sito Web a partire da un DB [1]. Questa
tecnica è detta “materializzazione
ipertestuale” del database e consente di superare i due principali
svantaggi della soluzione pull [20]: 1)
Evita il sovraccarico del DBMS, riducendo notevolmente il numero di
accessi. Infatti è necessario generare nuove pagine Web solo in
corrispondenza di un cambiamento di stato della base di dati, anziché ad ogni
richiesta di un utente. 2)
Permette la duplicazione remota del sito, rafforzando l’indipendenza
dalla piattaforma. Si usa talvolta il termine push
per quest’approccio, ad indicare che i dati vengono “spinti” in anticipo
verso il sito e, quindi, verso l’utente [1]. La materializzazione sta assumendo
un’importanza sempre maggiore nell’ambiente degli sviluppatori di siti
Web, anche perché può essere realizzata con gli stessi strumenti utilizzati
dalla tecnologia pull: script CGI, ASP o Cold Fusion, applicazioni Java, ecc.
Tuttavia essa non è sufficiente a costruire siti Web centrati sui dati, poiché
bisogna tener conto almeno di altri due aspetti: ·
la struttura ipertestuale del sito, costituita
dall’organizzazione in pagine del contenuto informativo e dalle modalità di
navigazione fra i dati; ·
la presentazione, che corrisponde agli aspetti
grafici e alla disposizione del contenuto e dei link all’interno delle
pagine. Esistono numerosi software per la
realizzazione di siti Web basati sui dati che affrontano anche questi
problemi. È possibile classificarli, in base ai loro pregi e limiti [21]: a)
Editor visuali, come NetObject Fusion, Macromedia Dreamweaver e
Microsoft FrontPage. Questa classe include ambienti di sviluppo
originariamente concepiti per alleviare le difficoltà di scrittura del codice
HTML e di manutenzione delle pagine del sito nel file system dell’host.
Tipicamente questi prodotti offrono un editor HTML, che consente all’utente
di realizzare pagine sofisticate senza programmare, e un file
manager che mostra graficamente il contenuto del sito, gestendo
automaticamente i collegamenti fra le varie pagine. b)
Applicazioni per la creazione di ipertesti multimediali su Web, come
Macromedia Director, Aimtech Iconauthor, e Quest, della Allen Communication.
Sono simili agli editor visuali, ma la loro origine è diversa: essi vennero
originariamente concepiti per progettare presentazioni multimediali off-line,
e successivamente è stato aggiunto loro il supporto per la creazione di siti
Web. Questi strumenti possono accedere a basi di dati, ma utilizzano soluzioni
proprietarie e di difficile portabilità. c)
Strumenti per l’integrazione tra Web e basi di dati, come Microsoft
ASP, Allaire Cold Fusion, Oracle PL/SQL Web Toolkit. Sono rivolti ai
programmatori, che possono usarli per inserire i risultati di interrogazioni
su DB nelle pagine Web. Tutti gli altri aspetti della realizzazione del sito
devono essere implementati manualmente o con altri mezzi. d)
Estensioni dei DBMS per la pubblicazione su Web: sono comprese nei
prodotti più importanti, come Microsoft Access, Oracle Developer 2000, Sybase
PowerBuilder. Esse generano siti completi ed efficienti, ma troppo aderenti a
modelli prestabiliti, lasciando, quindi, scarsa flessibilità nella scelta
della struttura ipertestuale e della presentazione del sito. e)
Generatori di applicazioni Web imperniati su un modello, come Hyperwave
Server 4.0 e Oracle Designer 2000. Essi sviluppano siti Web mettendo in atto
il principio fondamentale dell’ingegneria del software: la generazione del
codice deve essere preceduta da un modello concettuale. In particolare: ·
Hyperwave adotta un modello ipertestuale
semplificato, adatto a gestire la navigazione fra le pagine, ma carente per
quanto riguarda la rappresentazione delle informazioni ·
Oracle Designer 2000 estende il modello ER (vedi
§ 1.2.2) al progetto di siti Web, risultando, però, limitato nel controllo
della presentazione. f)
Progetti di ricerca, come Araneus dell’Università di Roma Tre,
Autoweb del Politecnico di Milano e Strudel della AT&T. Questi software si
occupano di tutte le attività di sviluppo dei siti Web centrati sui dati (dal
progetto alla manutenzione), organizzandole in un processo strutturato e
fornendo strumenti per automatizzare le operazioni ripetitive. Nel capitolo 3 ci occuperemo ampiamente
di Araneus, analizzando le applicazioni e i modelli logici che lo compongono e
valutando la sua capacità di realizzare siti composti da pagine HTML o XML.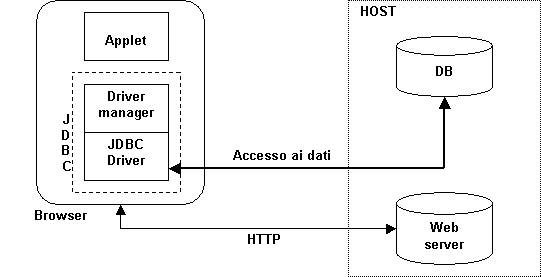
1.6.5
Sistemi con architettura a due livelli
1.6.6
Sistemi con architettura a tre livelli
1.7
Java servlet
import javax.servlet.*;
import java.util.*;
import java.io.*;
public class EchoRequest extends GenericServlet {
public String getServletInfo() {
return "Echo Request Servlet";
}
public void service(ServletRequest request, ServletResponse response)
throws ServletException, IOException {
response.setContentType("text/plain");
PrintStream outputStream = new PrintStream(response.getOutputStream());
outputStream.print("Server: "+request.getServerName()+":");
outputStream.println(request.getServerPort());
outputStream.print("Client: "+request.getRemoteHost()+" ");
outputStream.println(request.getRemoteAddr());
outputStream.println("Protocol: "+request.getProtocol());
Enumeration params = request.getParameterNames();
if(params != null) {
while(params.hasMoreElements()){
String param = (String) params.nextElement();
String value = request.getParameter(param);
outputStream.println(param+" = "+value);
}
}
}
}
1.7.1
Sistemi con architettura a tre livelli e uso dei servlet Java
1.8
Realizzazione automatica di siti Web a partire dai dati